 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoupled Recurrent Network (CRN)
Paper and Code
Dec 25, 2018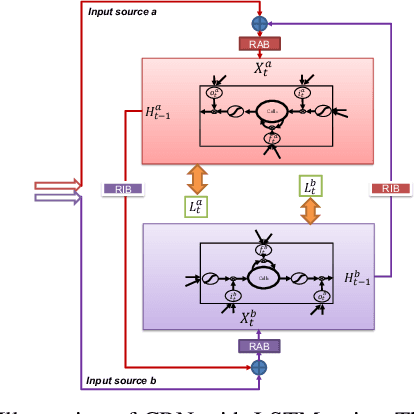
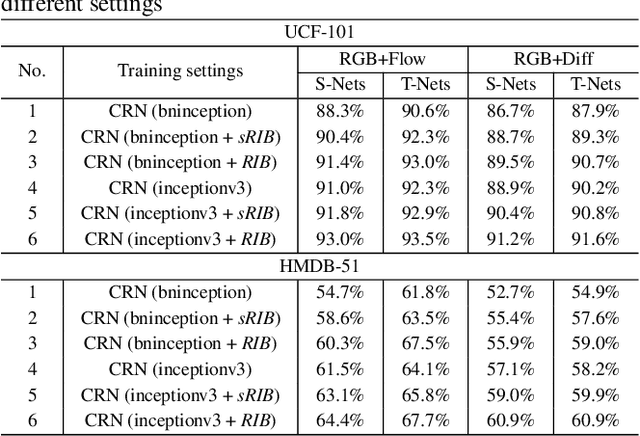
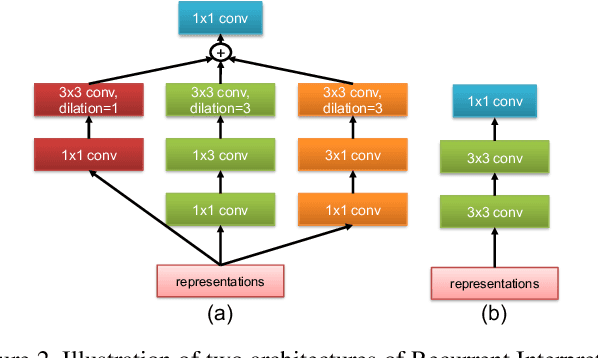
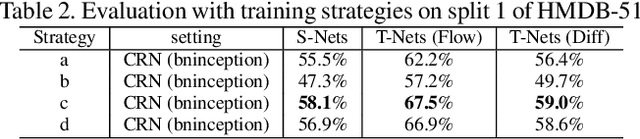
Many semantic video analysis tasks can benefit from multiple, heterogenous signals. For example, in addition to the original RGB input sequences, sequences of optical flow are usually used to boost the performance of human action recognition in videos. To learn from these heterogenous input sources, existing methods reply on two-stream architectural designs that contain independent, parallel streams of Recurrent Neural Networks (RNNs). However, two-stream RNNs do not fully exploit the reciprocal information contained in the multiple signals, let alone exploit it in a recurrent manner. To this end, we propose in this paper a novel recurrent architecture, termed Coupled Recurrent Network (CRN), to deal with multiple input sources. In CRN, the parallel streams of RNNs are coupled together. Key design of CRN is a Recurrent Interpretation Block (RIB) that supports learning of reciprocal feature representations from multiple signals in a recurrent manner. Different from RNNs which stack the training loss at each time step or the last time step, we propose an effective and efficient training strategy for CRN. Experiments show the efficacy of the proposed CRN. In particular, we achieve the new state of the art on the benchmark datasets of human action recognition and multi-person pose estimation.