 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOUGH: A Challenge Dataset and Models for COVID-19 FAQ Retrieval
Paper and Code
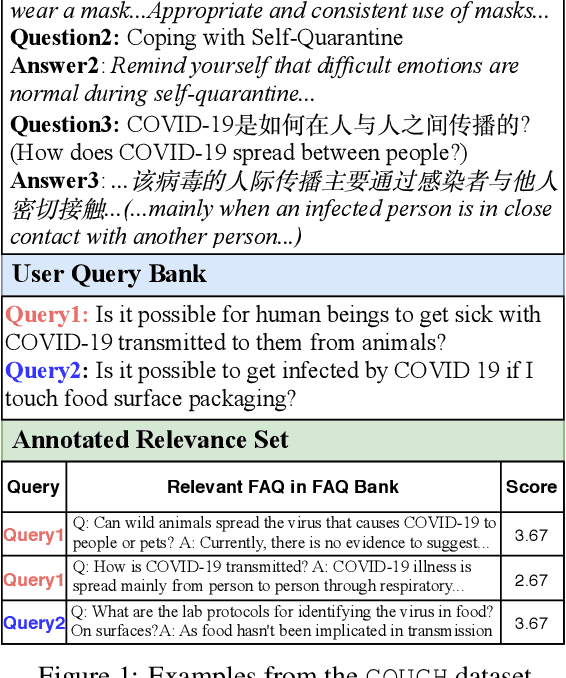
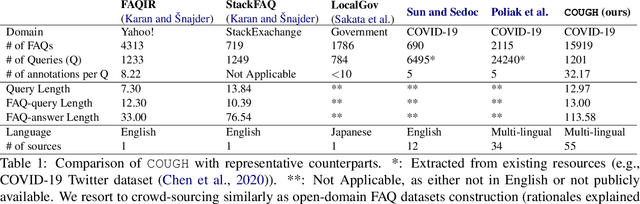
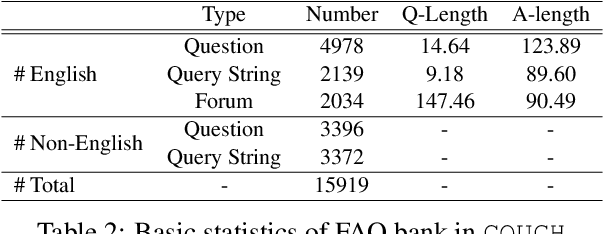
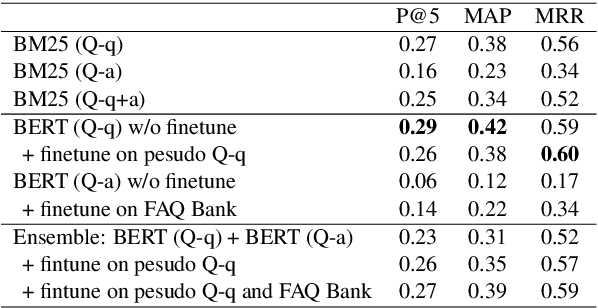
We present a large challenging dataset, COUGH, for COVID-19 FAQ retrieval. Specifically, similar to a standard FAQ dataset, COUGH consists of three parts: FAQ Bank, User Query Bank and Annotated Relevance Set. FAQ Bank contains ~16K FAQ items scraped from 55 credible websites (e.g., CDC and WHO). For evaluation, we introduce User Query Bank and Annotated Relevance Set, where the former contains 1201 human-paraphrased queries while the latter contains ~32 human-annotated FAQ items for each query. We analyze COUGH by testing different FAQ retrieval models built on top of BM25 and BERT, among which the best model achieves 0.29 under P@5, indicating that the dataset presents a great challenge for future research. Our dataset is freely available at https://github.com/sunlab-osu/covid-faq.