 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Tensor-Train LSTM for Spatio-temporal Learning
Paper and Code
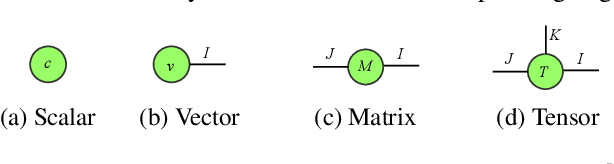
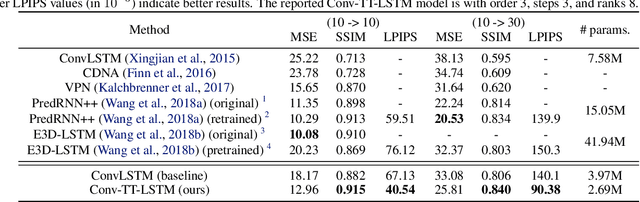

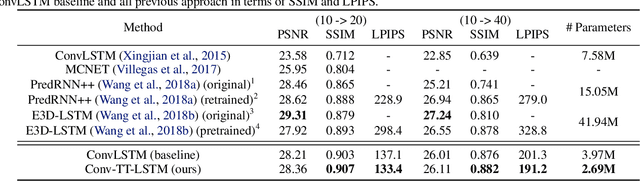
Higher-order Recurrent Neural Networks (RNNs) are effective for long-term forecasting since such architectures can model higher-order correlations and long-term dynamics more effectively. However, higher-order models are expensive and require exponentially more parameters and operations compared with their first-order counterparts. This problem is particularly pronounced in multidimensional data such as videos. To address this issue, we propose Convolutional Tensor-Train Decomposition (CTTD), a novel tensor decomposition with convolutional operations. With CTTD, we construct Convolutional Tensor-Train LSTM (Conv-TT-LSTM) to capture higher-order space-time correlations in videos. We demonstrate that the proposed model outperforms the conventional (first-order) Convolutional LSTM (ConvLSTM) as well as the state-of-the-art ConvLSTM-based approaches in pixel-level video prediction tasks on Moving-MNIST and KTH action datasets, but with much fewer parameters.