 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Gated Recurrent Networks for Video Segmentation
Paper and Code
Nov 21, 2016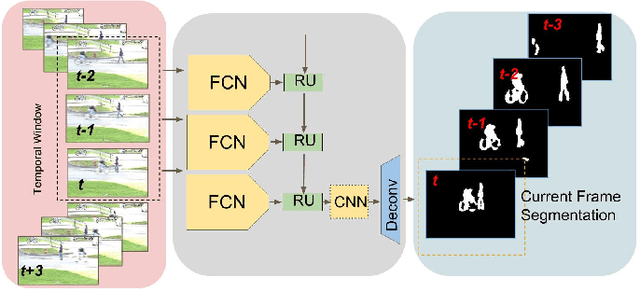



Semantic segmentation has recently witnessed major progress, where fully convolutional neural networks have shown to perform well. However, most of the previous work focused on improving single image segmentation. To our knowledge, no prior work has made use of temporal video information in a recurrent network. In this paper, we introduce a novel approach to implicitly utilize temporal data in videos for online semantic segmentation. The method relies on a fully convolutional network that is embedded into a gated recurrent architecture. This design receives a sequence of consecutive video frames and outputs the segmentation of the last frame. Convolutional gated recurrent networks are used for the recurrent part to preserve spatial connectivities in the image. Our proposed method can be applied in both online and batch segmentation. This architecture is tested for both binary and semantic video segmentation tasks. Experiments are conducted on the recent benchmarks in SegTrack V2, Davis, CityScapes, and Synthia. Using recurrent fully convolutional networks improved the baseline network performance in all of our experiments. Namely, 5% and 3% improvement of F-measure in SegTrack2 and Davis respectively, 5.7% improvement in mean IoU in Synthia and 3.5% improvement in categorical mean IoU in CityScapes. The performance of the RFCN network depends on its baseline fully convolutional network. Thus RFCN architecture can be seen as a method to improve its baseline segmentation network by exploiting spatiotemporal information in videos.