 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Video-Language Learning with Fine-grained Frame Sampling
Paper and Code
Oct 10, 2022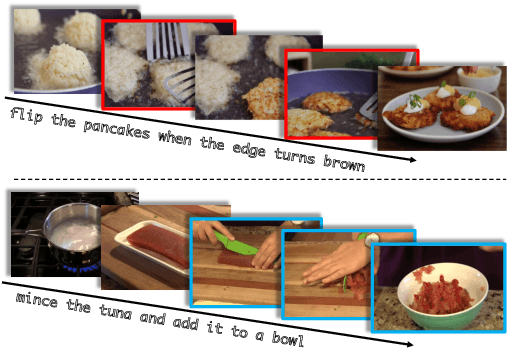
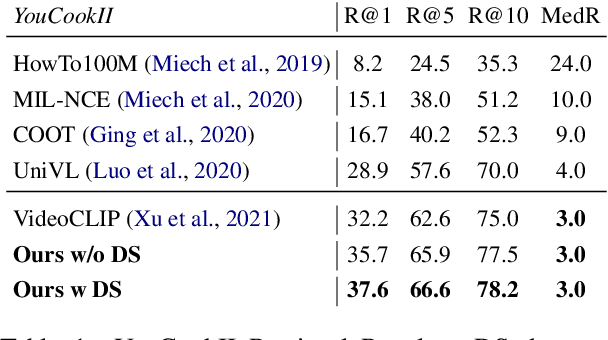
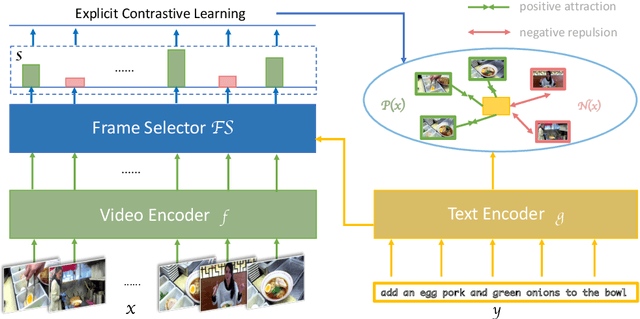
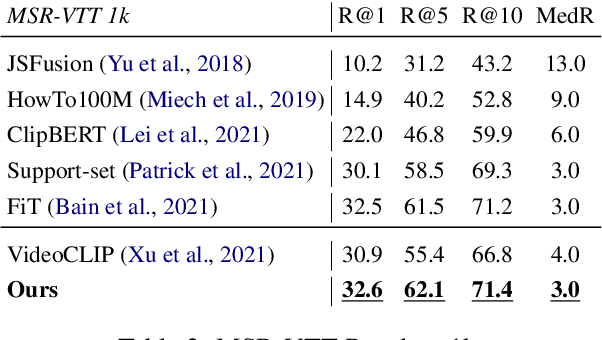
Despite recent progress in video and language representation learning, the weak or sparse correspondence between the two modalities remains a bottleneck in the area. Most video-language models are trained via pair-level loss to predict whether a pair of video and text is aligned. However, even in paired video-text segments, only a subset of the frames are semantically relevant to the corresponding text, with the remainder representing noise; where the ratio of noisy frames is higher for longer videos. We propose FineCo (Fine-grained Contrastive Loss for Frame Sampling), an approach to better learn video and language representations with a fine-grained contrastive objective operating on video frames. It helps distil a video by selecting the frames that are semantically equivalent to the text, improving cross-modal correspondence. Building on the well established VideoCLIP model as a starting point, FineCo achieves state-of-the-art performance on YouCookII, a text-video retrieval benchmark with long videos. FineCo also achieves competitive results on text-video retrieval (MSR-VTT), and video question answering datasets (MSR-VTT QA and MSR-VTT MC) with shorter videos.