 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuously Controllable Facial Expression Editing in Talking Face Videos
Paper and Code
Sep 17, 2022
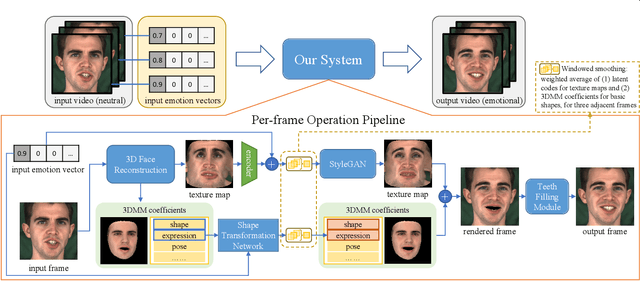
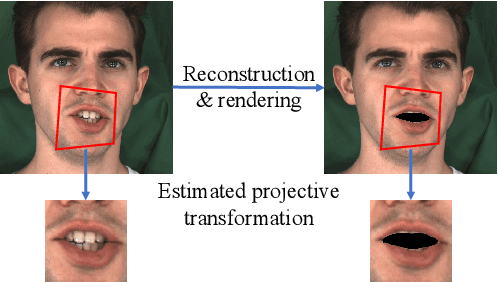

Recently audio-driven talking face video generation has attracted considerable attention. However, very few researches address the issue of emotional editing of these talking face videos with continuously controllable expressions, which is a strong demand in the industry. The challenge is that speech-related expressions and emotion-related expressions are often highly coupled. Meanwhile, traditional image-to-image translation methods cannot work well in our application due to the coupling of expressions with other attributes such as poses, i.e., translating the expression of the character in each frame may simultaneously change the head pose due to the bias of the training data distribution. In this paper, we propose a high-quality facial expression editing method for talking face videos, allowing the user to control the target emotion in the edited video continuously. We present a new perspective for this task as a special case of motion information editing, where we use a 3DMM to capture major facial movements and an associated texture map modeled by a StyleGAN to capture appearance details. Both representations (3DMM and texture map) contain emotional information and can be continuously modified by neural networks and easily smoothed by averaging in coefficient/latent spaces, making our method simple yet effective. We also introduce a mouth shape preservation loss to control the trade-off between lip synchronization and the degree of exaggeration of the edited expression. Extensive experiments and a user study show that our method achieves state-of-the-art performance across various evaluation criteria.