 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptualization Topic Modeling
Paper and Code
Apr 07, 2017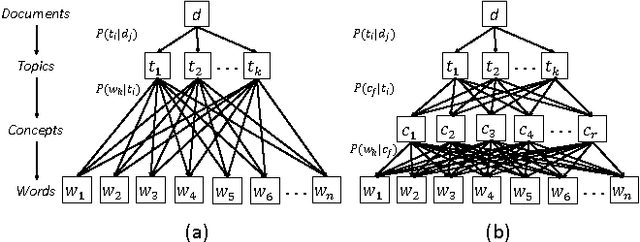
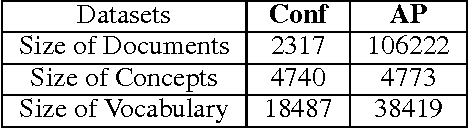
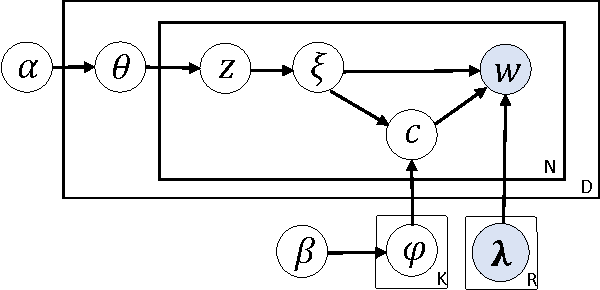
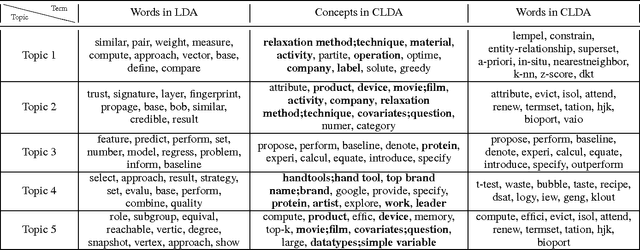
Recently, topic modeling has been widely used to discover the abstract topics in text corpora. Most of the existing topic models are based on the assumption of three-layer hierarchical Bayesian structure, i.e. each document is modeled as a probability distribution over topics, and each topic is a probability distribution over words. However, the assumption is not optimal. Intuitively, it's more reasonable to assume that each topic is a probability distribution over concepts, and then each concept is a probability distribution over words, i.e. adding a latent concept layer between topic layer and word layer in traditional three-layer assumption. In this paper, we verify the proposed assumption by incorporating the new assumption in two representative topic models, and obtain two novel topic models. Extensive experiments were conducted among the proposed models and corresponding baselines, and the results show that the proposed models significantly outperform the baselines in terms of case study and perplexity, which means the new assumption is more reasonable than traditional one.