 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Drift Detection and Adaptation with Hierarchical Hypothesis Testing
Paper and Code
Sep 17, 2018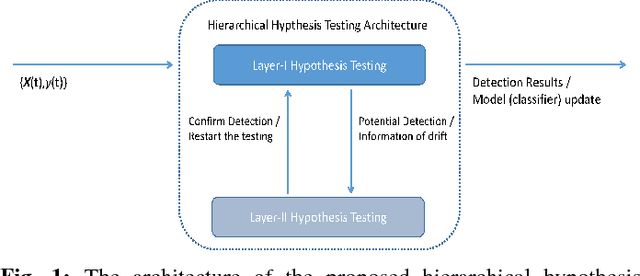
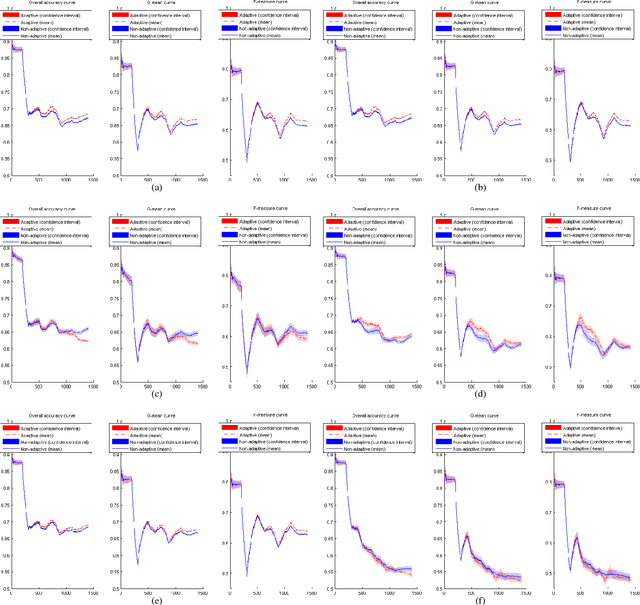
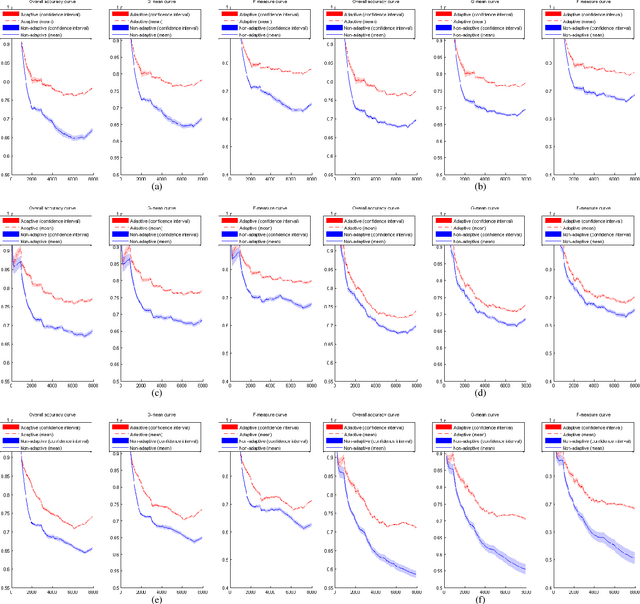
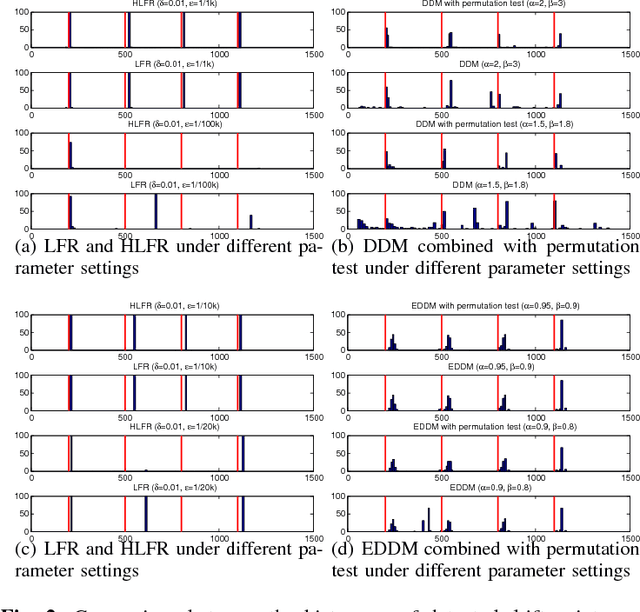
A fundamental issue for statistical classification models in a streaming environment is that the joint distribution between predictor and response variables changes over time (a phenomenon also known as concept drifts), such that their classification performance deteriorates dramatically. In this paper, we first present a hierarchical hypothesis testing (HHT) framework that can detect and also adapt to various concept drift types (e.g., recurrent or irregular, gradual or abrupt), even in the presence of imbalanced data labels. A novel concept drift detector, namely Hierarchical Linear Four Rates (HLFR), is implemented under the HHT framework thereafter. By substituting a widely-acknowledged retraining scheme with an adaptive training strategy, we further demonstrate that the concept drift adaptation capability of HLFR can be significantly boosted. The theoretical analysis on the Type-I and Type-II errors of HLFR is also performed. Experiments on both simulated and real-world datasets illustrate that our methods outperform state-of-the-art methods in terms of detection precision, detection delay as well as the adaptability across different concept drift types.