 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputation on Sparse Neural Networks: an Inspiration for Future Hardware
Paper and Code
Apr 24, 2020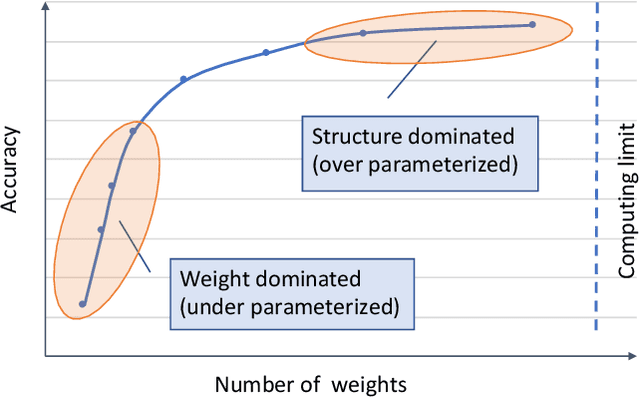
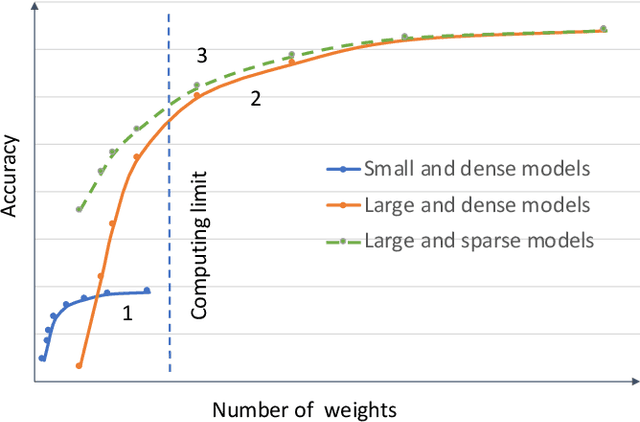
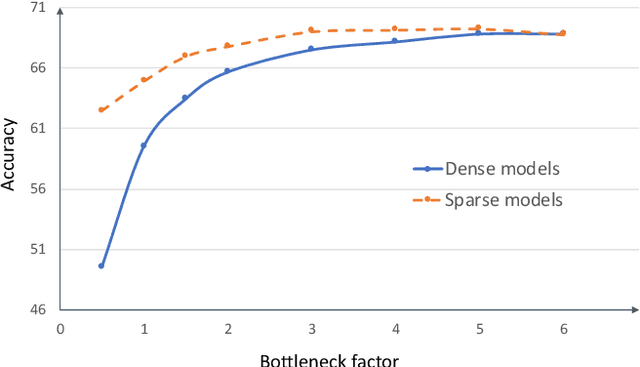
Neural network models are widely used in solving many challenging problems, such as computer vision, personalized recommendation, and natural language processing. Those models are very computationally intensive and reach the hardware limit of the existing server and IoT devices. Thus, finding better model architectures with much less amount of computation while maximally preserving the accuracy is a popular research topic. Among various mechanisms that aim to reduce the computation complexity, identifying the zero values in the model weights and in the activations to avoid computing them is a promising direction. In this paper, we summarize the current status of the research on the computation of sparse neural networks, from the perspective of the sparse algorithms, the software frameworks, and the hardware accelerations. We observe that the search for the sparse structure can be a general methodology for high-quality model explorations, in addition to a strategy for high-efficiency model execution. We discuss the model accuracy influenced by the number of weight parameters and the structure of the model. The corresponding models are called to be located in the weight dominated and structure dominated regions, respectively. We show that for practically complicated problems, it is more beneficial to search large and sparse models in the weight dominated region. In order to achieve the goal, new approaches are required to search for proper sparse structures, and new sparse training hardware needs to be developed to facilitate fast iterations of sparse models.