 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Video Prediction
Paper and Code

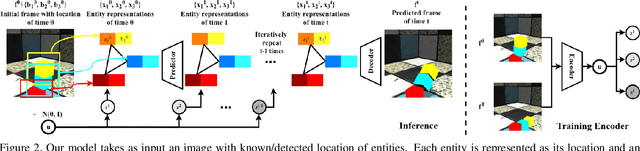
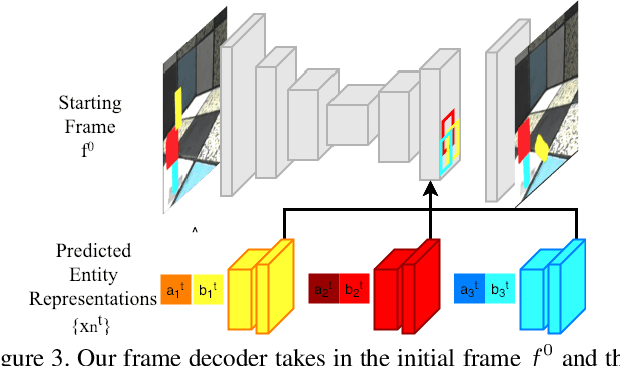
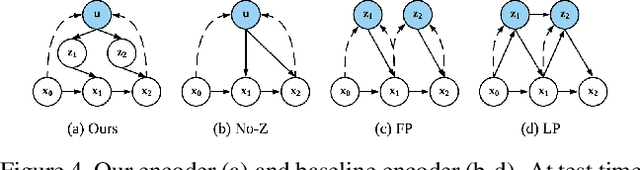
We present an approach for pixel-level future prediction given an input image of a scene. We observe that a scene is comprised of distinct entities that undergo motion and present an approach that operationalizes this insight. We implicitly predict future states of independent entities while reasoning about their interactions, and compose future video frames using these predicted states. We overcome the inherent multi-modality of the task using a global trajectory-level latent random variable, and show that this allows us to sample diverse and plausible futures. We empirically validate our approach against alternate representations and ways of incorporating multi-modality. We examine two datasets, one comprising of stacked objects that may fall, and the other containing videos of humans performing activities in a gym, and show that our approach allows realistic stochastic video prediction across these diverse settings. See https://judyye.github.io/CVP/ for video predictions.