 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication Efficient Distributed Kernel Principal Component Analysis
Paper and Code
Feb 13, 2016
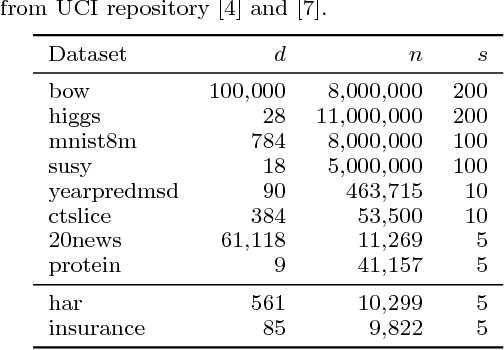
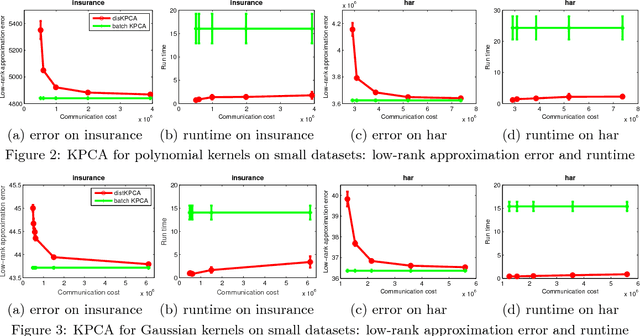
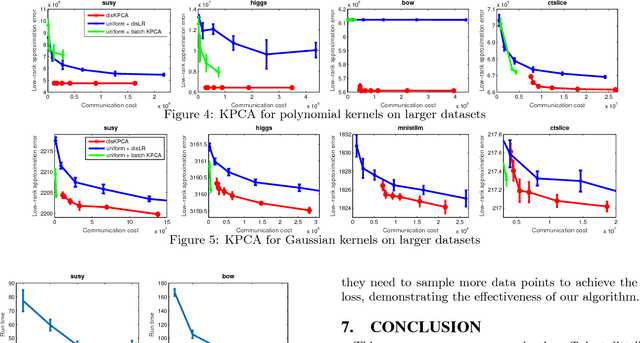
Kernel Principal Component Analysis (KPCA) is a key machine learning algorithm for extracting nonlinear features from data. In the presence of a large volume of high dimensional data collected in a distributed fashion, it becomes very costly to communicate all of this data to a single data center and then perform kernel PCA. Can we perform kernel PCA on the entire dataset in a distributed and communication efficient fashion while maintaining provable and strong guarantees in solution quality? In this paper, we give an affirmative answer to the question by developing a communication efficient algorithm to perform kernel PCA in the distributed setting. The algorithm is a clever combination of subspace embedding and adaptive sampling techniques, and we show that the algorithm can take as input an arbitrary configuration of distributed datasets, and compute a set of global kernel principal components with relative error guarantees independent of the dimension of the feature space or the total number of data points. In particular, computing $k$ principal components with relative error $\epsilon$ over $s$ workers has communication cost $\tilde{O}(s \rho k/\epsilon+s k^2/\epsilon^3)$ words, where $\rho$ is the average number of nonzero entries in each data point. Furthermore, we experimented the algorithm with large-scale real world datasets and showed that the algorithm produces a high quality kernel PCA solution while using significantly less communication than alternative approaches.