 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommonGen: A Constrained Text Generation Dataset Towards Generative Commonsense Reasoning
Paper and Code


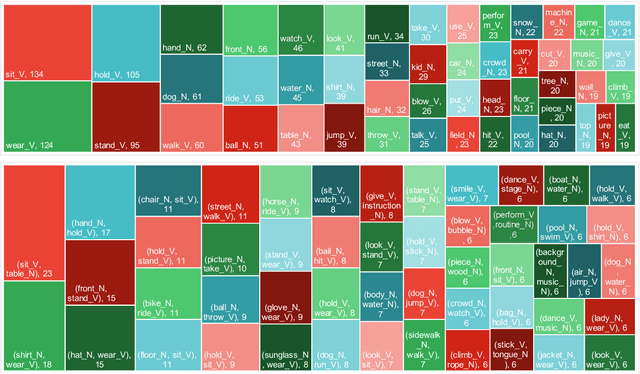
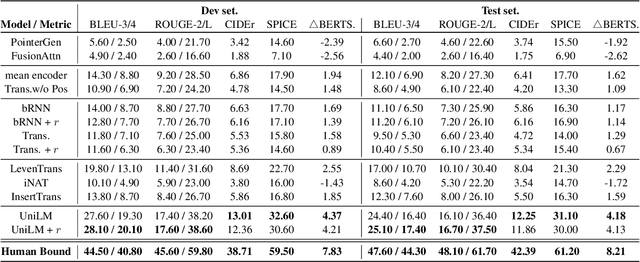
Rational humans can generate sentences that cover a certain set of concepts while describing natural and common scenes. For example, given {apple(noun), tree(noun), pick(verb)}, humans can easily come up with scenes like "a boy is picking an apple from a tree" via their generative commonsense reasoning ability. However, we find this capacity has not been well learned by machines. Most prior works in machine commonsense focus on discriminative reasoning tasks with a multi-choice question answering setting. Herein, we present CommonGen: a challenging dataset for testing generative commonsense reasoning with a constrained text generation task. We collect 37k concept-sets as inputs and 90k human-written sentences as associated outputs. Additionally, we also provide high-quality rationales behind the reasoning process for the development and test sets from the human annotators. We demonstrate the difficulty of the task by examining a wide range of sequence generation methods with both automatic metrics and human evaluation. The state-of-the-art pre-trained generation model, UniLM, is still far from human performance in this task. Our data and code is publicly available at http://inklab.usc.edu/CommonGen/ .