 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining the Best of Convolutional Layers and Recurrent Layers: A Hybrid Network for Semantic Segmentation
Paper and Code
Mar 15, 2016
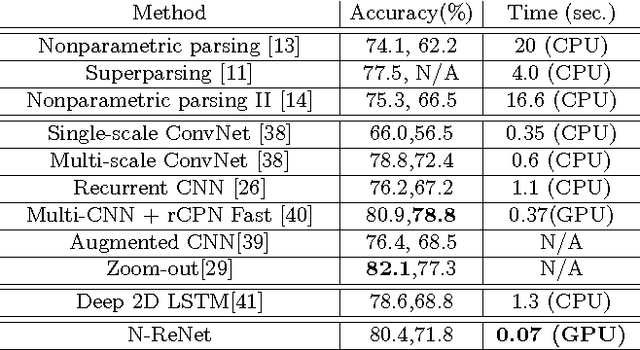


State-of-the-art results of semantic segmentation are established by Fully Convolutional neural Networks (FCNs). FCNs rely on cascaded convolutional and pooling layers to gradually enlarge the receptive fields of neurons, resulting in an indirect way of modeling the distant contextual dependence. In this work, we advocate the use of spatially recurrent layers (i.e. ReNet layers) which directly capture global contexts and lead to improved feature representations. We demonstrate the effectiveness of ReNet layers by building a Naive deep ReNet (N-ReNet), which achieves competitive performance on Stanford Background dataset. Furthermore, we integrate ReNet layers with FCNs, and develop a novel Hybrid deep ReNet (H-ReNet). It enjoys a few remarkable properties, including full-image receptive fields, end-to-end training, and efficient network execution. On the PASCAL VOC 2012 benchmark, the H-ReNet improves the results of state-of-the-art approaches Piecewise, CRFasRNN and DeepParsing by 3.6%, 2.3% and 0.2%, respectively, and achieves the highest IoUs for 13 out of the 20 object classes.