 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombing Policy Evaluation and Policy Improvement in a Unified f-Divergence Framework
Paper and Code
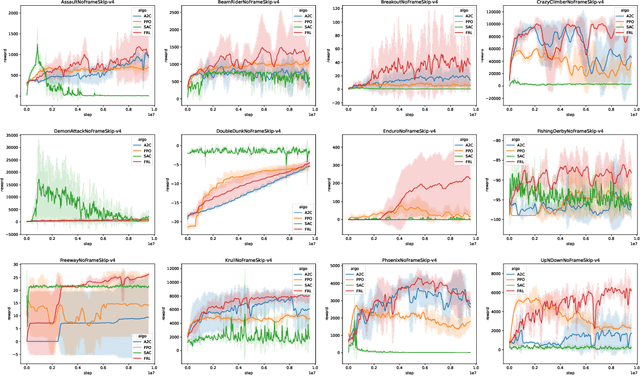
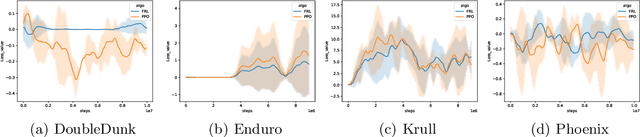
The framework of deep reinforcement learning (DRL) provides a powerful and widely applicable mathematical formalization for sequential decision-making. In this paper, we start from studying the f-divergence between learning policy and sampling policy and derive a novel DRL framework, termed f-Divergence Reinforcement Learning (FRL). We highlight that the policy evaluation and policy improvement phases are induced by minimizing f-divergence between learning policy and sampling policy, which is distinct from the conventional DRL algorithm objective that maximizes the expected cumulative rewards. Besides, we convert this framework to a saddle-point optimization problem with a specific f function through Fenchel conjugate, which consists of policy evaluation and policy improvement. Then we derive new policy evaluation and policy improvement methods in FRL. Our framework may give new insights for analyzing DRL algorithms. The FRL framework achieves two advantages: (1) policy evaluation and policy improvement processes are derived simultaneously by f-divergence; (2) overestimation issue of value function are alleviated. To evaluate the effectiveness of the FRL framework, we conduct experiments on Atari 2600 video games, which show that our framework matches or surpasses the DRL algorithms we tested.