 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMATH: Can Your Language Model Pass Chinese Elementary School Math Test?
Paper and Code
Jun 29, 2023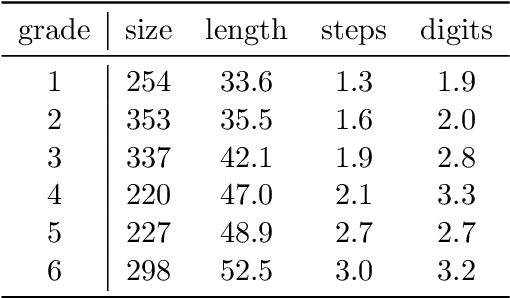

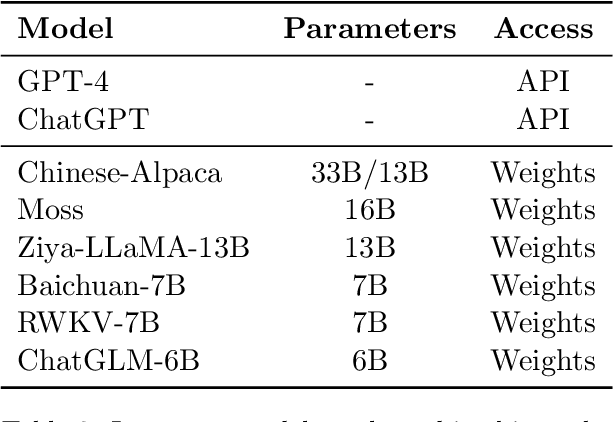

We present the Chinese Elementary School Math Word Problems (CMATH) dataset, comprising 1.7k elementary school-level math word problems with detailed annotations, source from actual Chinese workbooks and exams. This dataset aims to provide a benchmark tool for assessing the following question: to what grade level of elementary school math do the abilities of popular large language models (LLMs) correspond? We evaluate a variety of popular LLMs, including both commercial and open-source options, and discover that only GPT-4 achieves success (accuracy $\geq$ 60\%) across all six elementary school grades, while other models falter at different grade levels. Furthermore, we assess the robustness of several top-performing LLMs by augmenting the original problems in the CMATH dataset with distracting information. Our findings reveal that GPT-4 is able to maintains robustness, while other model fail. We anticipate that our study will expose limitations in LLMs' arithmetic and reasoning capabilities, and promote their ongoing development and advancement.