 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCluster Analysis of a Symbolic Regression Search Space
Paper and Code
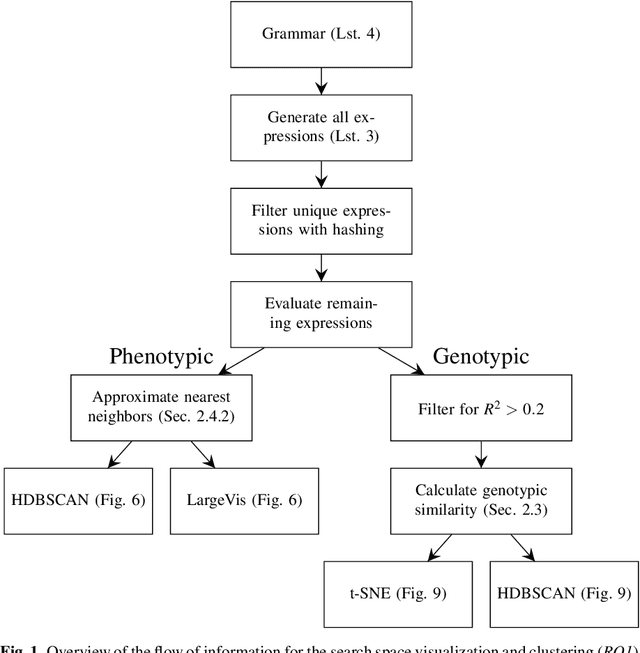
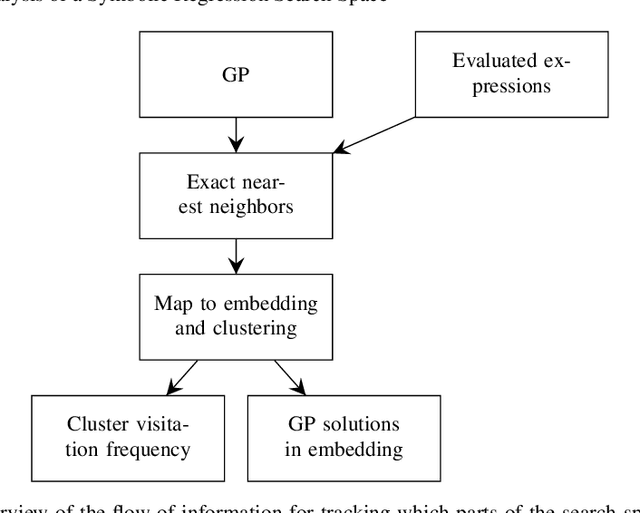

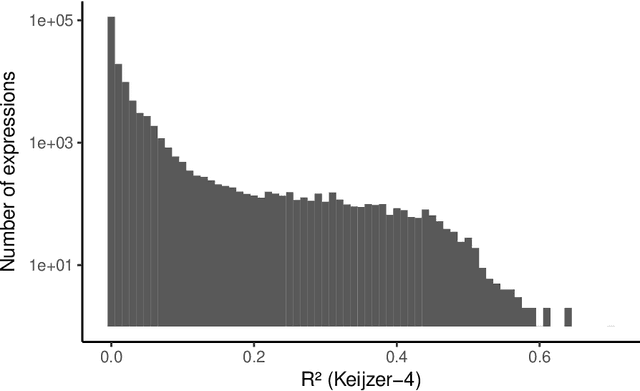
In this chapter we take a closer look at the distribution of symbolic regression models generated by genetic programming in the search space. The motivation for this work is to improve the search for well-fitting symbolic regression models by using information about the similarity of models that can be precomputed independently from the target function. For our analysis, we use a restricted grammar for uni-variate symbolic regression models and generate all possible models up to a fixed length limit. We identify unique models and cluster them based on phenotypic as well as genotypic similarity. We find that phenotypic similarity leads to well-defined clusters while genotypic similarity does not produce a clear clustering. By mapping solution candidates visited by GP to the enumerated search space we find that GP initially explores the whole search space and later converges to the subspace of highest quality expressions in a run for a simple benchmark problem.