 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosed-book Question Generation via Contrastive Learning
Paper and Code
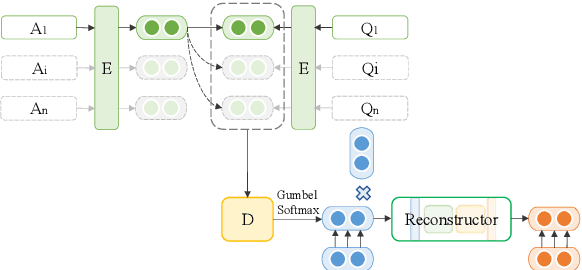



Question Generation (QG) is a fundamental NLP task for many downstream applications. Recent studies on open-book QG, where supportive question-context pairs are provided to models, have achieved promising progress. However, generating natural questions under a more practical closed-book setting that lacks these supporting documents still remains a challenge. In this work, to learn better representations from semantic information hidden in question-answer pairs under the closed-book setting, we propose a new QG model empowered by a contrastive learning module and an answer reconstruction module. We present a new closed-book QA dataset -- WikiCQA involving abstractive long answers collected from a wiki-style website. In the experiments, we validate the proposed QG model on both public datasets and the new WikiCQA dataset. Empirical results show that the proposed QG model outperforms baselines in both automatic evaluation and human evaluation. In addition, we show how to leverage the proposed model to improve existing closed-book QA systems. We observe that by pre-training a closed-book QA model on our generated synthetic QA pairs, significant QA improvement can be achieved on both seen and unseen datasets, which further demonstrates the effectiveness of our QG model for enhancing unsupervised and semi-supervised QA.