 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLOMO: Counterfactual Logical Modification with Large Language Models
Paper and Code
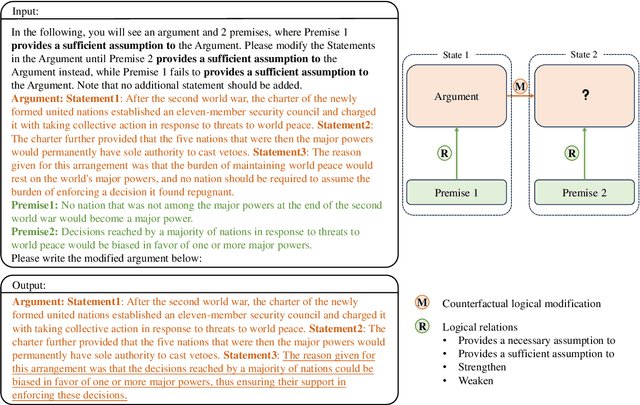
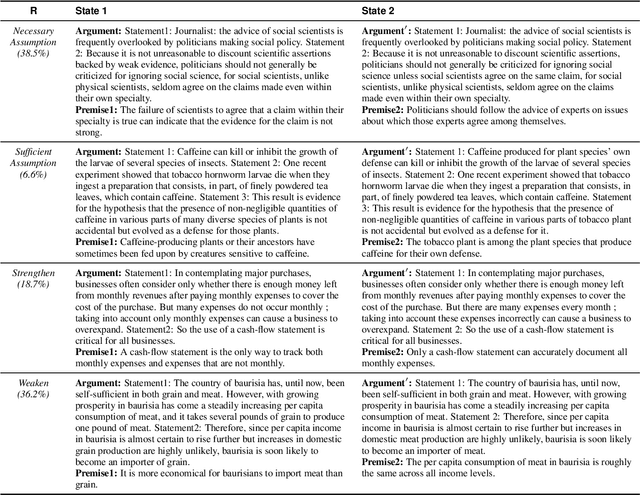
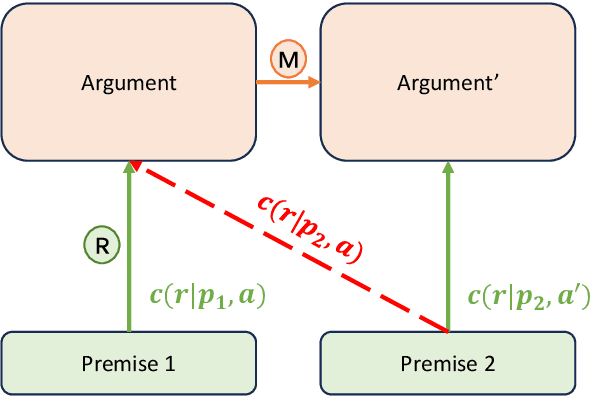

In this study, we delve into the realm of counterfactual reasoning capabilities of large language models (LLMs). Our primary objective is to cultivate the counterfactual thought processes within LLMs and rigorously assess these processes for their validity. Specifically, we introduce a novel task, Counterfactual Logical Modification (CLOMO), and a high-quality human-annotated benchmark. In this task, LLMs must adeptly alter a given argumentative text to uphold a predetermined logical relationship. To effectively evaluate a generation model's counterfactual capabilities, we propose an innovative evaluation metric, the LogicAware Counterfactual Score to directly evaluate the natural language output of LLMs instead of modeling the task as a multiple-choice problem. Analysis shows that the proposed automatic metric aligns well with human preference. Our experimental results show that while LLMs demonstrate a notable capacity for logical counterfactual thinking, there remains a discernible gap between their current abilities and human performance.