 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEAR: Generative Counterfactual Explanations on Graphs
Paper and Code
Oct 16, 2022
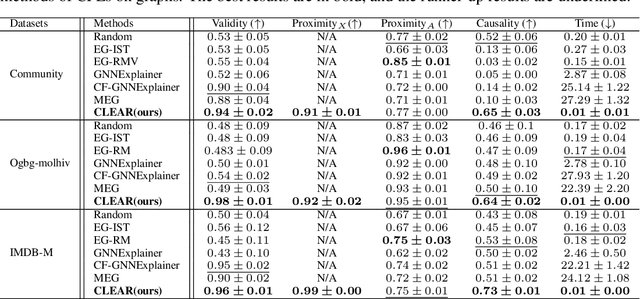


Counterfactual explanations promote explainability in machine learning models by answering the question "how should an input instance be perturbed to obtain a desired predicted label?". The comparison of this instance before and after perturbation can enhance human interpretation. Most existing studies on counterfactual explanations are limited in tabular data or image data. In this work, we study the problem of counterfactual explanation generation on graphs. A few studies have explored counterfactual explanations on graphs, but many challenges of this problem are still not well-addressed: 1) optimizing in the discrete and disorganized space of graphs; 2) generalizing on unseen graphs; and 3) maintaining the causality in the generated counterfactuals without prior knowledge of the causal model. To tackle these challenges, we propose a novel framework CLEAR which aims to generate counterfactual explanations on graphs for graph-level prediction models. Specifically, CLEAR leverages a graph variational autoencoder based mechanism to facilitate its optimization and generalization, and promotes causality by leveraging an auxiliary variable to better identify the underlying causal model. Extensive experiments on both synthetic and real-world graphs validate the superiority of CLEAR over the state-of-the-art methods in different aspects.