 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel-Temporal Attention for First-Person Video Domain Adaptation
Paper and Code
Aug 19, 2021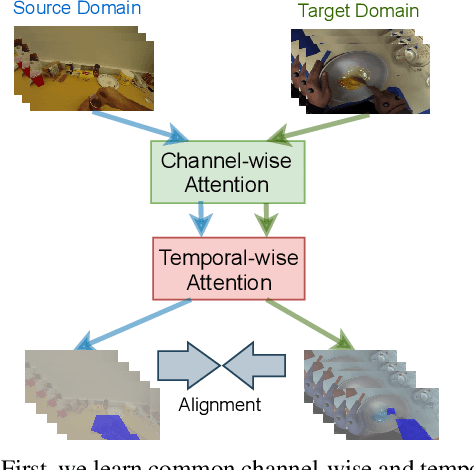
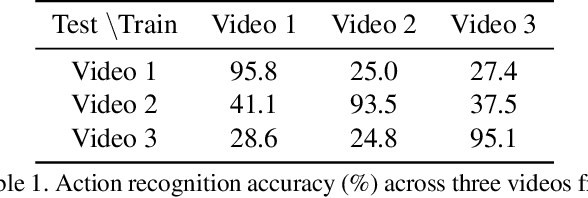

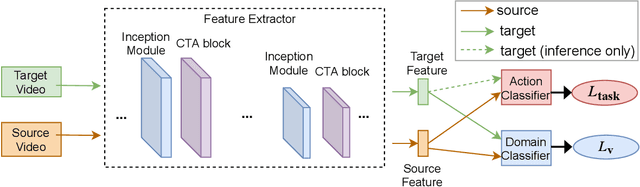
Unsupervised Domain Adaptation (UDA) can transfer knowledge from labeled source data to unlabeled target data of the same categories. However, UDA for first-person action recognition is an under-explored problem, with lack of datasets and limited consideration of first-person video characteristics. This paper focuses on addressing this problem. Firstly, we propose two small-scale first-person video domain adaptation datasets: ADL$_{small}$ and GTEA-KITCHEN. Secondly, we introduce channel-temporal attention blocks to capture the channel-wise and temporal-wise relationships and model their inter-dependencies important to first-person vision. Finally, we propose a Channel-Temporal Attention Network (CTAN) to integrate these blocks into existing architectures. CTAN outperforms baselines on the two proposed datasets and one existing dataset EPIC$_{cvpr20}$.