 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
Paper and Code


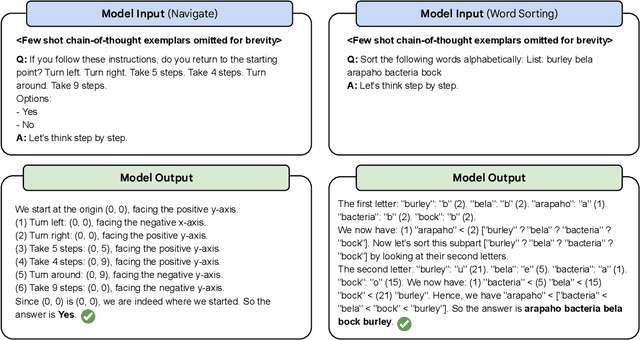

BIG-Bench (Srivastava et al., 2022) is a diverse evaluation suite that focuses on tasks believed to be beyond the capabilities of current language models. Language models have already made good progress on this benchmark, with the best model in the BIG-Bench paper outperforming average reported human-rater results on 65% of the BIG-Bench tasks via few-shot prompting. But on what tasks do language models fall short of average human-rater performance, and are those tasks actually unsolvable by current language models? In this work, we focus on a suite of 23 challenging BIG-Bench tasks which we call BIG-Bench Hard (BBH). These are the task for which prior language model evaluations did not outperform the average human-rater. We find that applying chain-of-thought (CoT) prompting to BBH tasks enables PaLM to surpass the average human-rater performance on 10 of the 23 tasks, and Codex (code-davinci-002) to surpass the average human-rater performance on 17 of the 23 tasks. Since many tasks in BBH require multi-step reasoning, few-shot prompting without CoT, as done in the BIG-Bench evaluations (Srivastava et al., 2022), substantially underestimates the best performance and capabilities of language models, which is better captured via CoT prompting. As further analysis, we explore the interaction between CoT and model scale on BBH, finding that CoT enables emergent task performance on several BBH tasks with otherwise flat scaling curves.