 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertified Robustness to Label-Flipping Attacks via Randomized Smoothing
Paper and Code
Feb 07, 2020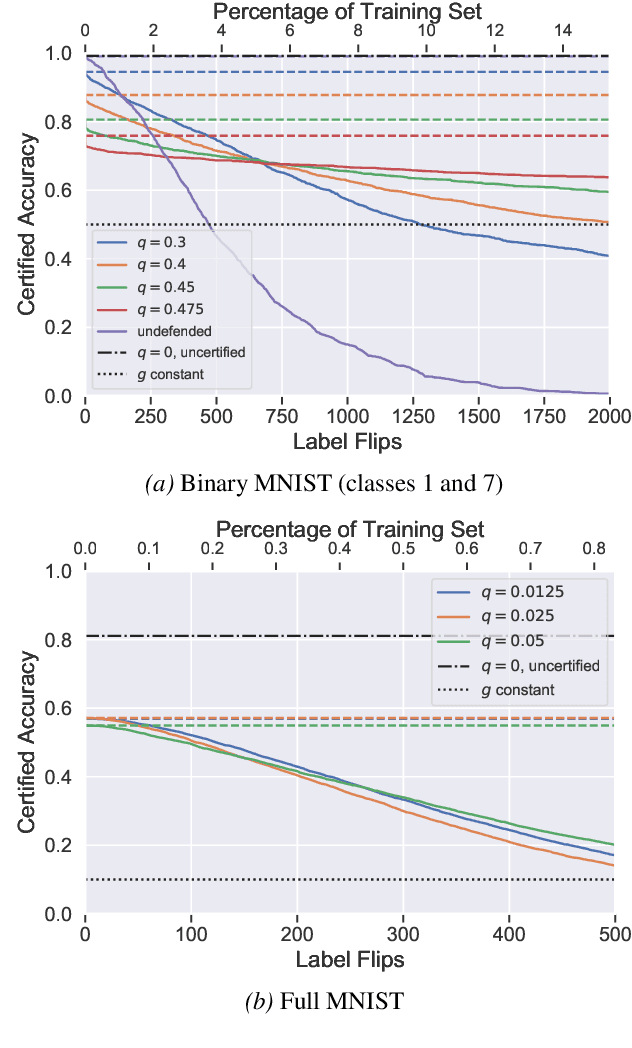
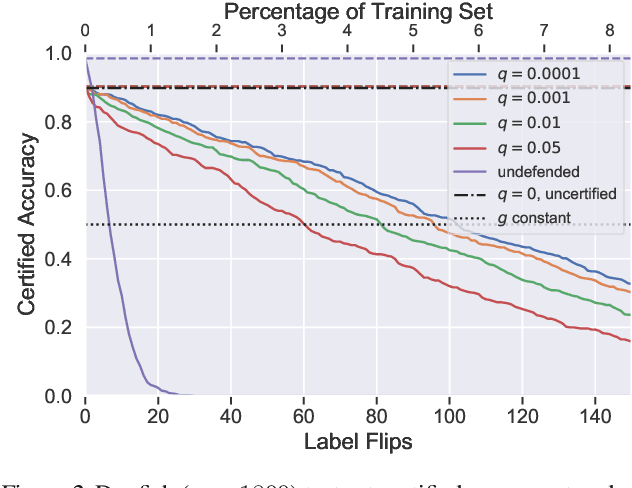
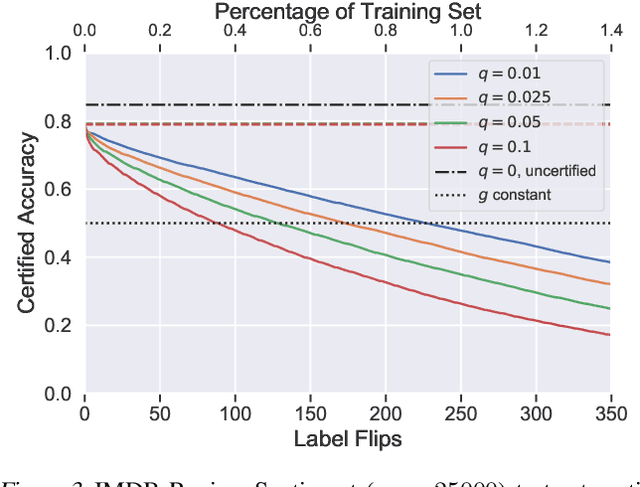
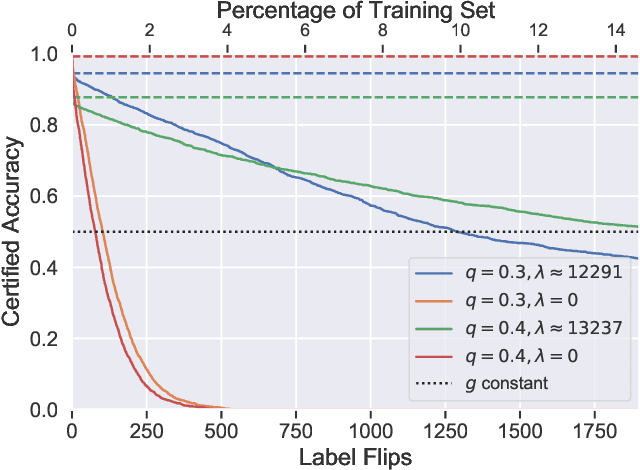
Machine learning algorithms are known to be susceptible to data poisoning attacks, where an adversary manipulates the training data to degrade performance of the resulting classifier. While many heuristic defenses have been proposed, few defenses exist which are certified against worst-case corruption of the training data. In this work, we propose a strategy to build linear classifiers that are certifiably robust against a strong variant of label-flipping, where each test example is targeted independently. In other words, for each test point, our classifier makes a prediction and includes a certification that its prediction would be the same had some number of training labels been changed adversarially. Our approach leverages randomized smoothing, a technique that has previously been used to guarantee---with high probability---test-time robustness to adversarial manipulation of the input to a classifier. We derive a variant which provides a deterministic, analytical bound, sidestepping the probabilistic certificates that traditionally result from the sampling subprocedure. Further, we obtain these certified bounds with no additional runtime cost over standard classification. We generalize our results to the multi-class case, providing what we believe to be the first multi-class classification algorithm that is certifiably robust to label-flipping attacks.