 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascade Attention Network for Person Search: Both Image and Text-Image Similarity Selection
Paper and Code
Sep 22, 2018
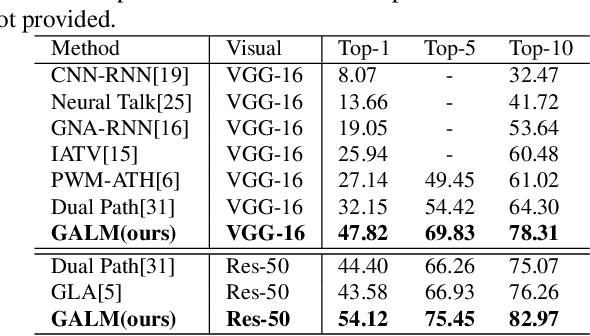

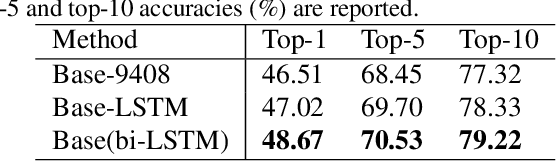
Person search with natural language aims to retrieve the corresponding person in an image database by virtue of a describing sentence about the person, which poses great potential for many applications, e.g., video surveillance. Extracting corresponding visual contents to the human description is the key to this cross-modal matching problem. In this paper, we propose a cascade attention network (CAN) to progressively select from person image and text-image similarity. In the CAN, a pose-guided attention is first proposed to attend to the person in the augmented input which concatenates original 3 image channels with another 14 pose confidence maps. With the extracted person image representation, we compute the local similarities between person parts and textual description. Then a similarity-based hard attention is proposed to further select the description-related similarity scores from those local similarities. To verify the effectiveness of our model, we perform extensive experiments on the CUHK Person Description Dataset (CUHK-PEDES) which is currently the only dataset for person search with natural language. Experimental results show that our approach outperforms the state-of-the-art methods by a large margin.