 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaption Feature Space Regularization for Audio Captioning
Paper and Code

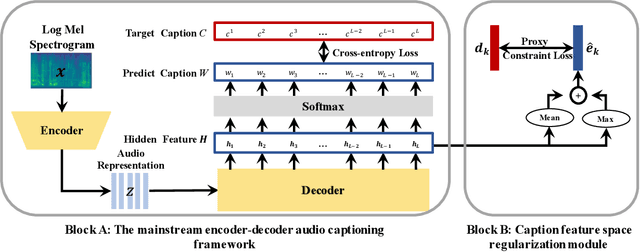
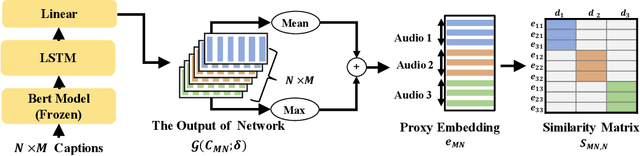

Audio captioning aims at describing the content of audio clips with human language. Due to the ambiguity of audio, different people may perceive the same audio differently, resulting in caption disparities (i.e., one audio may correlate to several captions with diverse semantics). For that, general audio captioning models achieve the one-to-many training by randomly selecting a correlated caption as the ground truth for each audio. However, it leads to a significant variation in the optimization directions and weakens the model stability. To eliminate this negative effect, in this paper, we propose a two-stage framework for audio captioning: (i) in the first stage, via the contrastive learning, we construct a proxy feature space to reduce the distances between captions correlated to the same audio, and (ii) in the second stage, the proxy feature space is utilized as additional supervision to encourage the model to be optimized in the direction that benefits all the correlated captions. We conducted extensive experiments on two datasets using four commonly used encoder and decoder architectures. Experimental results demonstrate the effectiveness of the proposed method. The code is available at https://github.com/PRIS-CV/Caption-Feature-Space-Regularization.