 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCancerBERT: a BERT model for Extracting Breast Cancer Phenotypes from Electronic Health Records
Paper and Code
Aug 25, 2021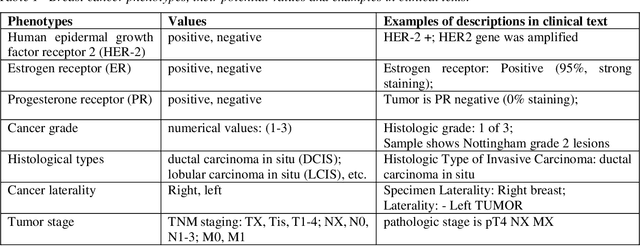

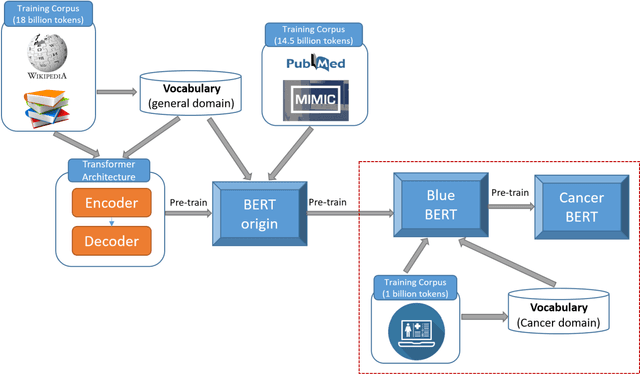
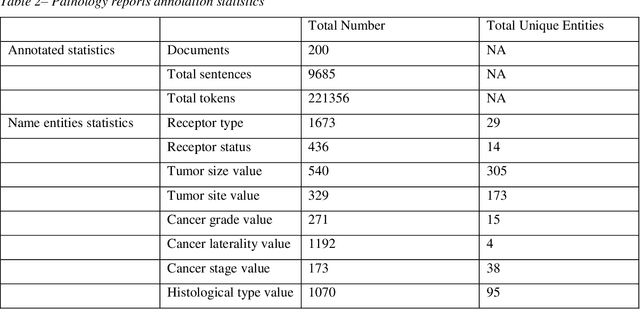
Accurate extraction of breast cancer patients' phenotypes is important for clinical decision support and clinical research. Current models do not take full advantage of cancer domain-specific corpus, whether pre-training Bidirectional Encoder Representations from Transformer model on cancer-specific corpus could improve the performances of extracting breast cancer phenotypes from texts data remains to be explored. The objective of this study is to develop and evaluate the CancerBERT model for extracting breast cancer phenotypes from clinical texts in electronic health records. This data used in the study included 21,291 breast cancer patients diagnosed from 2010 to 2020, patients' clinical notes and pathology reports were collected from the University of Minnesota Clinical Data Repository (UMN). Results: About 3 million clinical notes and pathology reports in electronic health records for 21,291 breast cancer patients were collected to train the CancerBERT model. 200 pathology reports and 50 clinical notes of breast cancer patients that contain 9,685 sentences and 221,356 tokens were manually annotated by two annotators. 20% of the annotated data was used as a test set. Our CancerBERT model achieved the best performance with macro F1 scores equal to 0.876 (95% CI, 0.896-0.902) for exact match and 0.904 (95% CI, 0.896-0.902) for the lenient match. The NER models we developed would facilitate the automated information extraction from clinical texts to further help clinical decision support. Conclusions and Relevance: In this study, we focused on the breast cancer-related concepts extraction from EHR data and obtained a comprehensive annotated dataset that contains 7 types of breast cancer-related concepts. The CancerBERT model with customized vocabulary could significantly improve the performance for extracting breast cancer phenotypes from clinical texts.