 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Self-Supervised Learning solve the problem of child speech recognition?
Paper and Code
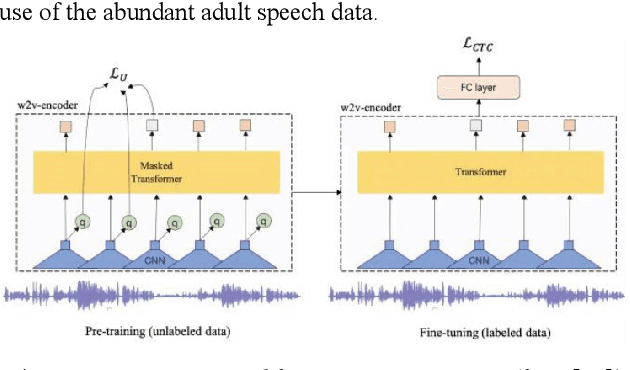
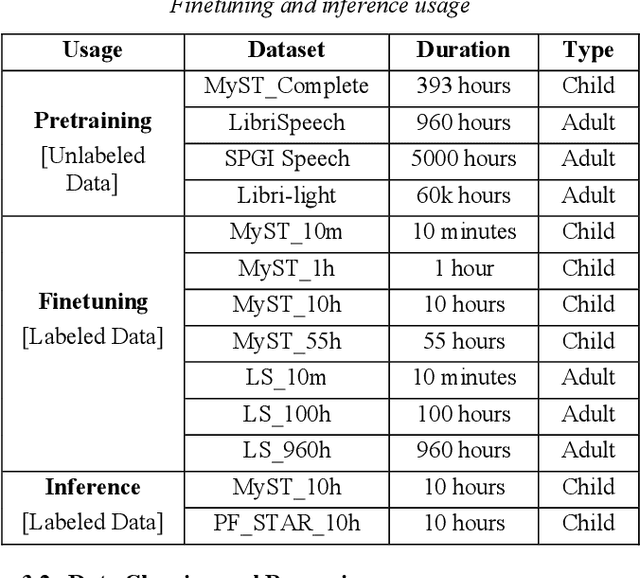
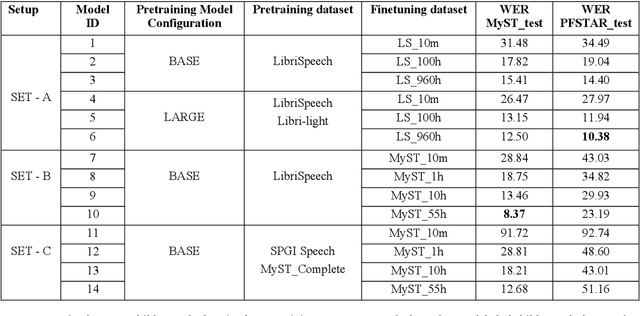
Despite recent advancements in deep learning technologies, Child Speech Recognition remains a challenging task. Current Automatic Speech Recognition (ASR) models required substantial amounts of annotated data for training, which is scarce. In this work, we explore using the ASR model, wav2vec2, with different pretraining and finetuning configurations for self supervised learning (SSL) towards improving automatic child speech recognition. The pretrained wav2vec2 models were finetuned using different amounts of child speech training data to discover the optimum amount of data required to finetune the model for the task of child ASR. Our trained model receives the best word error rate (WER) of 8.37 on the in domain MyST dataset and WER of 10.38 on the out of domain PFSTAR dataset. We do not use any Language Models (LM) in our experiments.