 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan OpenAI Codex and Other Large Language Models Help Us Fix Security Bugs?
Paper and Code
Dec 03, 2021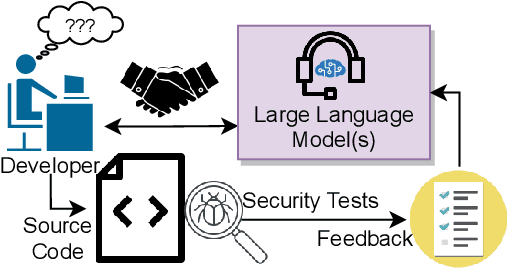
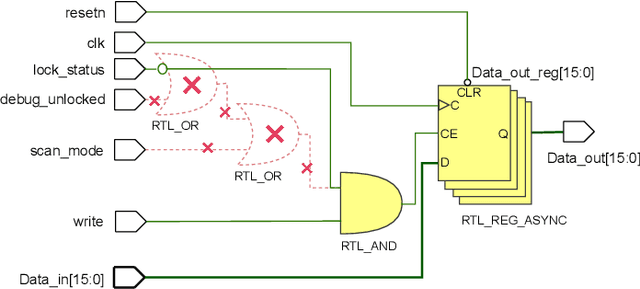
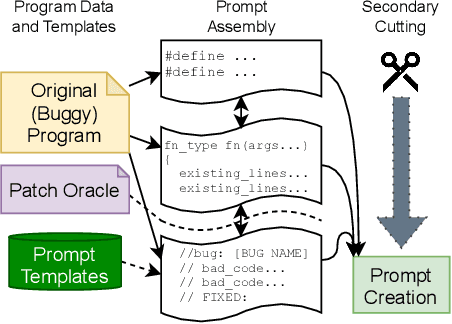

Human developers can produce code with cybersecurity weaknesses. Can emerging 'smart' code completion tools help repair those weaknesses? In this work, we examine the use of large language models (LLMs) for code (such as OpenAI's Codex and AI21's Jurassic J-1) for zero-shot vulnerability repair. We investigate challenges in the design of prompts that coax LLMs into generating repaired versions of insecure code. This is difficult due to the numerous ways to phrase key information -- both semantically and syntactically -- with natural languages. By performing a large scale study of four commercially available, black-box, "off-the-shelf" LLMs, as well as a locally-trained model, on a mix of synthetic, hand-crafted, and real-world security bug scenarios, our experiments show that LLMs could collectively repair 100% of our synthetically generated and hand-crafted scenarios, as well as 58% of vulnerabilities in a selection of historical bugs in real-world open-source projects.