 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrated Predictive Distributions via Diagnostics for Conditional Coverage
Paper and Code
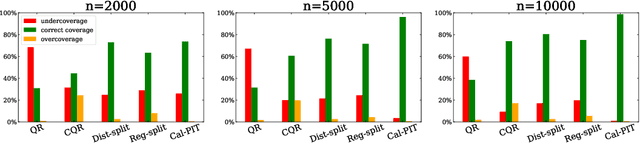

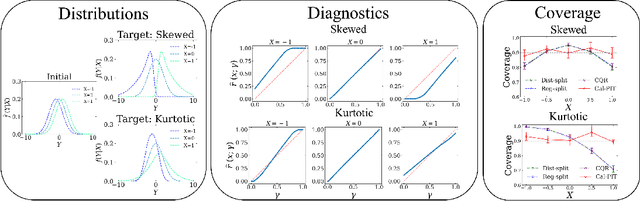
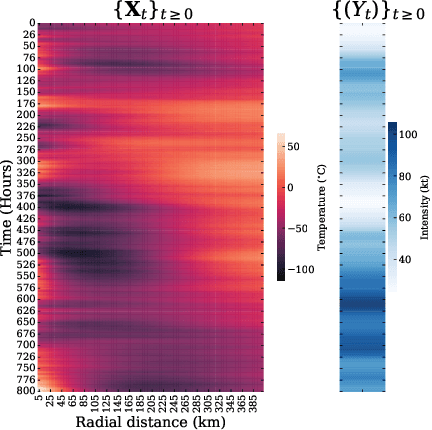
Uncertainty quantification is crucial for assessing the predictive ability of AI algorithms. A large body of work (including normalizing flows and Bayesian neural networks) has been devoted to describing the entire predictive distribution (PD) of a target variable Y given input features $\mathbf{X}$. However, off-the-shelf PDs are usually far from being conditionally calibrated; i.e., the probability of occurrence of an event given input $\mathbf{X}$ can be significantly different from the predicted probability. Most current research on predictive inference (such as conformal prediction) concerns constructing prediction sets, that do not only provide correct uncertainties on average over the entire population (that is, averaging over $\mathbf{X}$), but that are also approximately conditionally calibrated with accurate uncertainties for individual instances. It is often believed that the problem of obtaining and assessing entire conditionally calibrated PDs is too challenging to approach. In this work, we show that recalibration as well as validation are indeed attainable goals in practice. Our proposed method relies on the idea of regressing probability integral transform (PIT) scores against $\mathbf{X}$. This regression gives full diagnostics of conditional coverage across the entire feature space and can be used to recalibrate misspecified PDs. We benchmark our corrected prediction bands against oracle bands and state-of-the-art predictive inference algorithms for synthetic data, including settings with distributional shift and dependent high-dimensional sequence data. Finally, we demonstrate an application to the physical sciences in which we assess and produce calibrated PDs for measurements of galaxy distances using imaging data (i.e., photometric redshifts).