 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Sequential Inference Models for End-to-End Response Selection
Paper and Code

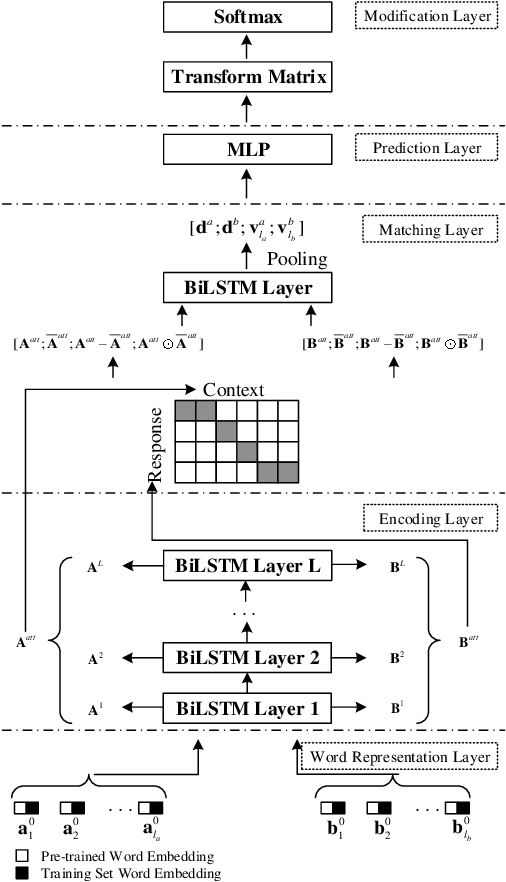
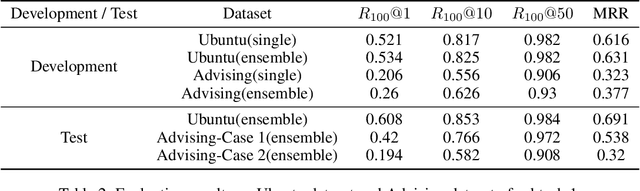
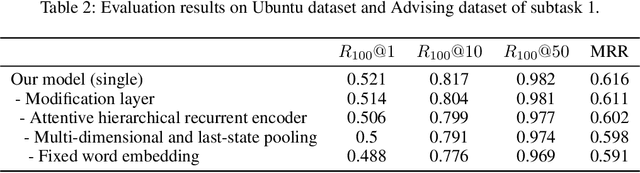
This paper presents an end-to-end response selection model for Track 1 of the 7th Dialogue System Technology Challenges (DSTC7). This task focuses on selecting the correct next utterance from a set of candidates given a partial conversation. We propose an end-to-end neural network based on enhanced sequential inference model (ESIM) for this task. Our proposed model differs from the original ESIM model in the following four aspects. First, a new word representation method which combines the general pre-trained word embeddings with those estimated on the task-specific training set is adopted in order to address the challenge of out-of-vocabulary (OOV) words. Second, an attentive hierarchical recurrent encoder (AHRE) is designed which is capable to encode sentences hierarchically and generate more descriptive representations by aggregation. Third, a new pooling method which combines multi-dimensional pooling and last-state pooling is used instead of the simple combination of max pooling and average pooling in the original ESIM. Last, a modification layer is added before the softmax layer to emphasize the importance of the last utterance in the context for response selection. In the released evaluation results of DSTC7, our proposed method ranked second on the Ubuntu dataset and third on the Advising dataset in subtask 1 of Track 1.