 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBT-Nets: Simplifying Deep Neural Networks via Block Term Decomposition
Paper and Code

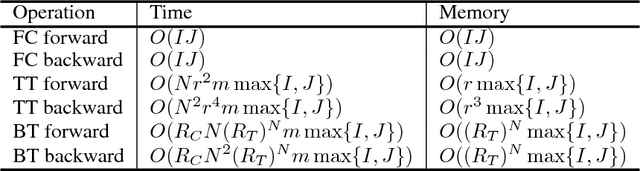

Recently, deep neural networks (DNNs) have been regarded as the state-of-the-art classification methods in a wide range of applications, especially in image classification. Despite the success, the huge number of parameters blocks its deployment to situations with light computing resources. Researchers resort to the redundancy in the weights of DNNs and attempt to find how fewer parameters can be chosen while preserving the accuracy at the same time. Although several promising results have been shown along this research line, most existing methods either fail to significantly compress a well-trained deep network or require a heavy fine-tuning process for the compressed network to regain the original performance. In this paper, we propose the \textit{Block Term} networks (BT-nets) in which the commonly used fully-connected layers (FC-layers) are replaced with block term layers (BT-layers). In BT-layers, the inputs and the outputs are reshaped into two low-dimensional high-order tensors, then block-term decomposition is applied as tensor operators to connect them. We conduct extensive experiments on benchmark datasets to demonstrate that BT-layers can achieve a very large compression ratio on the number of parameters while preserving the representation power of the original FC-layers as much as possible. Specifically, we can get a higher performance while requiring fewer parameters compared with the tensor train method.