Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounding Counterfactuals under Selection Bias
Paper and Code
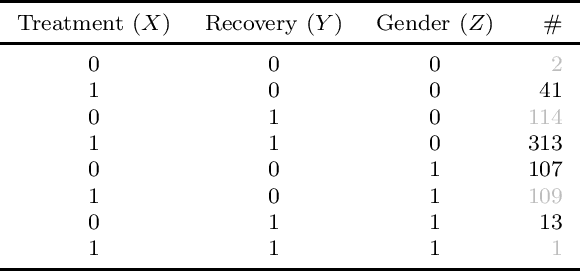
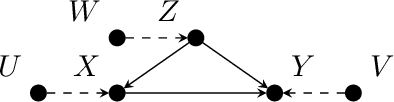
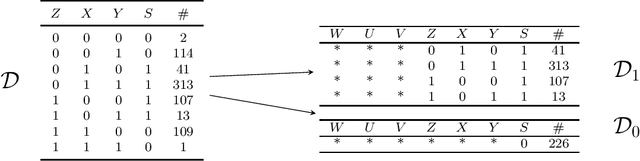
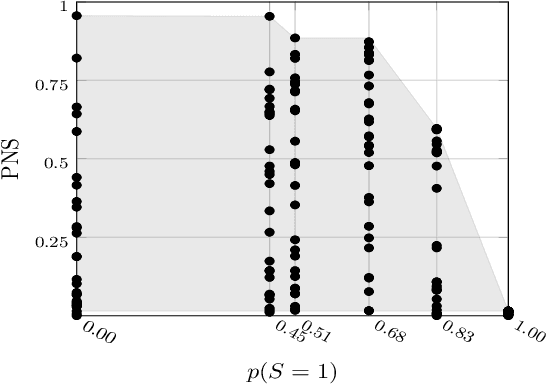
Causal analysis may be affected by selection bias, which is defined as the systematic exclusion of data from a certain subpopulation. Previous work in this area focused on the derivation of identifiability conditions. We propose instead a first algorithm to address both identifiable and unidentifiable queries. We prove that, in spite of the missingness induced by the selection bias, the likelihood of the available data is unimodal. This enables us to use the causal expectation-maximisation scheme to obtain the values of causal queries in the identifiable case, and to compute bounds otherwise. Experiments demonstrate the approach to be practically viable. Theoretical convergence characterisations are provided.
* Eleventh International Conference on Probabilistic Graphical Models
(PGM 2022)
View paper on