 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Neural Machine Translation with Dependency-Scaled Self-Attention Network
Paper and Code
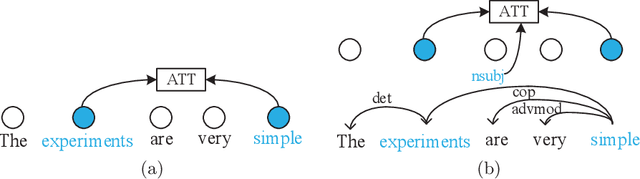
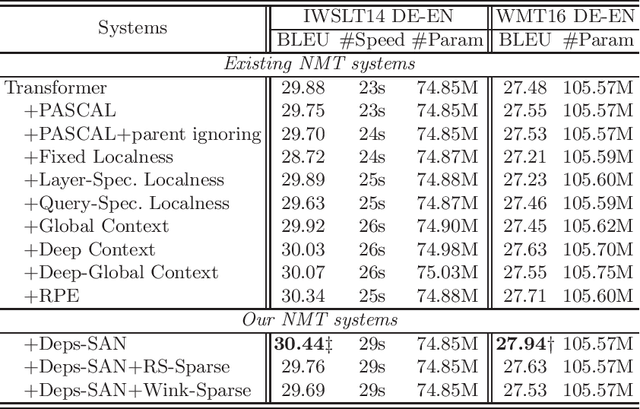
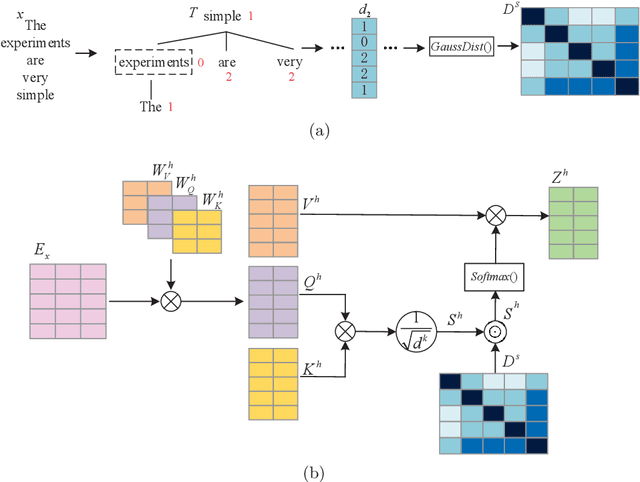
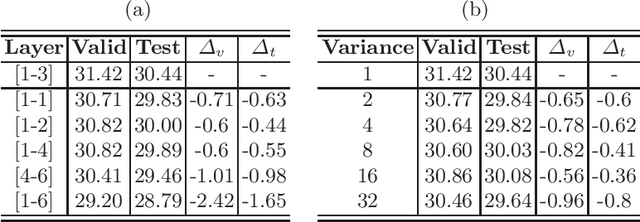
The neural machine translation model assumes that syntax knowledge can be learned from the bilingual corpus via an attention network automatically. However, the attention network trained in weak supervision actually cannot capture the deep structure of the sentence. Naturally, we expect to introduce external syntax knowledge to guide the learning of the attention network. Thus, we propose a novel, parameter-free, dependency-scaled self-attention network, which integrates explicit syntactic dependencies into the attention network to dispel the dispersion of attention distribution. Finally, two knowledge sparse techniques are proposed to prevent the model from overfitting noisy syntactic dependencies. Experiments and extensive analyses on the IWSLT14 German-to-English and WMT16 German-to-English translation tasks validate the effectiveness of our approach.