 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Few-Shot Visual Learning with Self-Supervision
Paper and Code
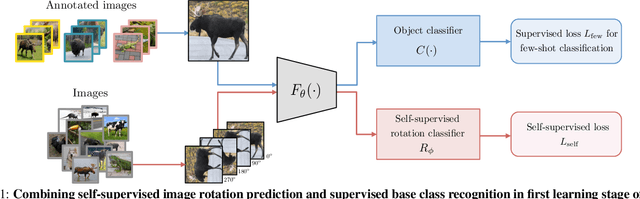
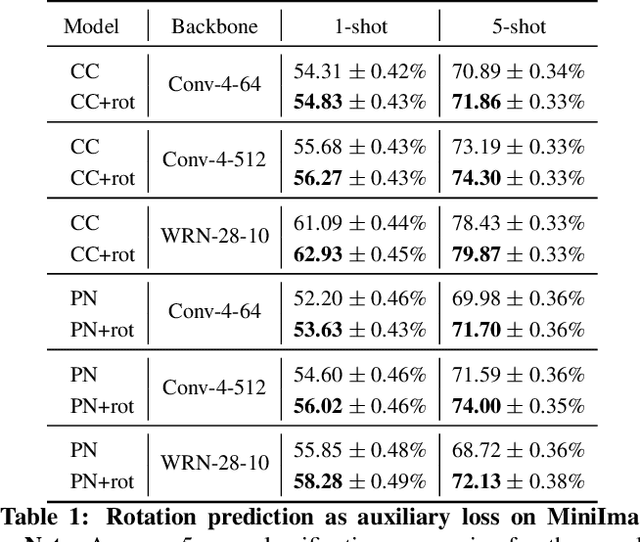
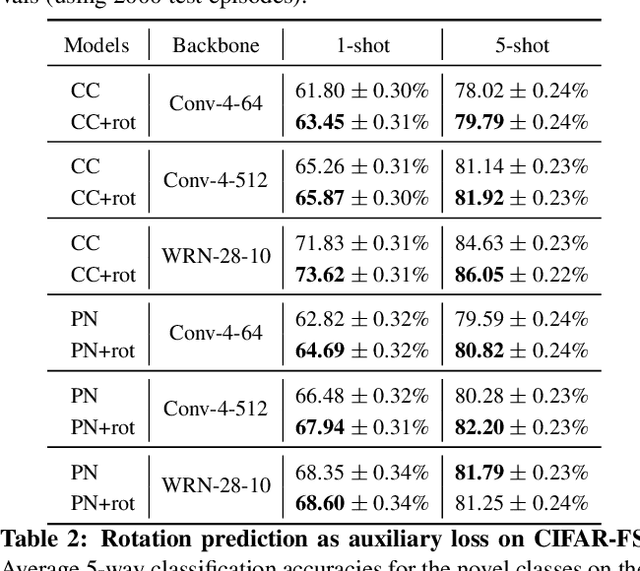
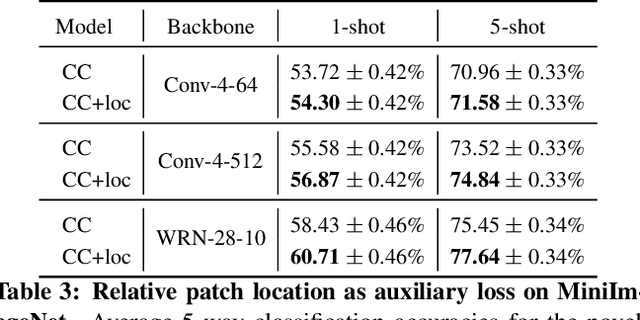
Few-shot learning and self-supervised learning address different facets of the same problem: how to train a model with little or no labeled data. Few-shot learning aims for optimization methods and models that can learn efficiently to recognize patterns in the low data regime. Self-supervised learning focuses instead on unlabeled data and looks into it for the supervisory signal to feed high capacity deep neural networks. In this work we exploit the complementarity of these two domains and propose an approach for improving few-shot learning through self-supervision. We use self-supervision as an auxiliary task in a few-shot learning pipeline, enabling feature extractors to learn richer and more transferable visual representations while still using few annotated samples. Through self-supervision, our approach can be naturally extended towards using diverse unlabeled data from other datasets in the few-shot setting. We report consistent improvements across an array of architectures, datasets and self-supervision techniques.