 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioMamba: A Pre-trained Biomedical Language Representation Model Leveraging Mamba
Paper and Code

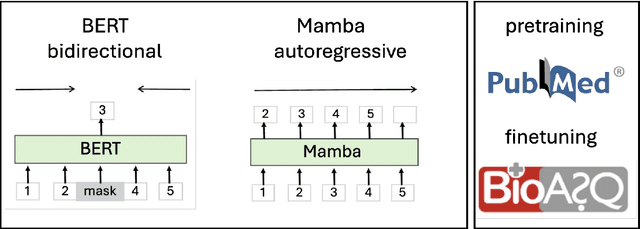
The advancement of natural language processing (NLP) in biology hinges on models' ability to interpret intricate biomedical literature. Traditional models often struggle with the complex and domain-specific language in this field. In this paper, we present BioMamba, a pre-trained model specifically designed for biomedical text mining. BioMamba builds upon the Mamba architecture and is pre-trained on an extensive corpus of biomedical literature. Our empirical studies demonstrate that BioMamba significantly outperforms models like BioBERT and general-domain Mamba across various biomedical tasks. For instance, BioMamba achieves a 100 times reduction in perplexity and a 4 times reduction in cross-entropy loss on the BioASQ test set. We provide an overview of the model architecture, pre-training process, and fine-tuning techniques. Additionally, we release the code and trained model to facilitate further research.