 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-Calibration Networks for Weakly-Supervised Video Representation Learning
Paper and Code


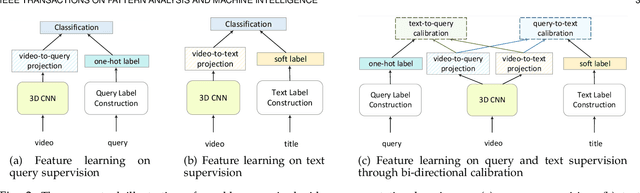
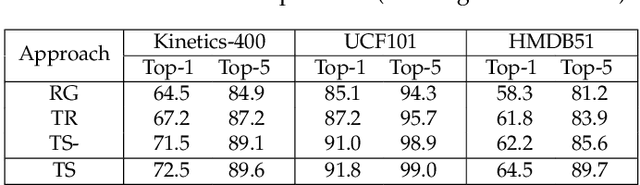
The leverage of large volumes of web videos paired with the searched queries or surrounding texts (e.g., title) offers an economic and extensible alternative to supervised video representation learning. Nevertheless, modeling such weakly visual-textual connection is not trivial due to query polysemy (i.e., many possible meanings for a query) and text isomorphism (i.e., same syntactic structure of different text). In this paper, we introduce a new design of mutual calibration between query and text to boost weakly-supervised video representation learning. Specifically, we present Bi-Calibration Networks (BCN) that novelly couples two calibrations to learn the amendment from text to query and vice versa. Technically, BCN executes clustering on all the titles of the videos searched by an identical query and takes the centroid of each cluster as a text prototype. The query vocabulary is built directly on query words. The video-to-text/video-to-query projections over text prototypes/query vocabulary then start the text-to-query or query-to-text calibration to estimate the amendment to query or text. We also devise a selection scheme to balance the two corrections. Two large-scale web video datasets paired with query and title for each video are newly collected for weakly-supervised video representation learning, which are named as YOVO-3M and YOVO-10M, respectively. The video features of BCN learnt on 3M web videos obtain superior results under linear model protocol on downstream tasks. More remarkably, BCN trained on the larger set of 10M web videos with further fine-tuning leads to 1.6%, and 1.8% gains in top-1 accuracy on Kinetics-400, and Something-Something V2 datasets over the state-of-the-art TDN, and ACTION-Net methods with ImageNet pre-training. Source code and datasets are available at \url{https://github.com/FuchenUSTC/BCN}.