 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Lipschitz: Sharp Generalization and Excess Risk Bounds for Full-Batch GD
Paper and Code
Apr 26, 2022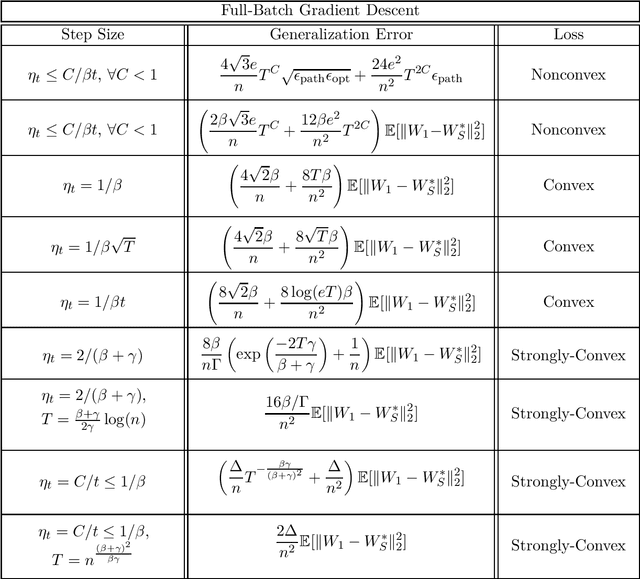
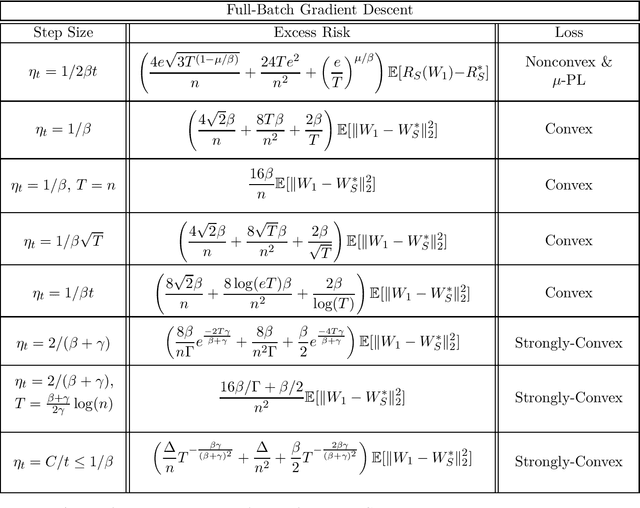
We provide sharp path-dependent generalization and excess error guarantees for the full-batch Gradient Decent (GD) algorithm for smooth losses (possibly non-Lipschitz, possibly nonconvex). At the heart of our analysis is a novel generalization error technique for deterministic symmetric algorithms, that implies average output stability and a bounded expected gradient of the loss at termination leads to generalization. This key result shows that small generalization error occurs at stationary points, and allows us to bypass Lipschitz assumptions on the loss prevalent in previous work. For nonconvex, convex and strongly convex losses, we show the explicit dependence of the generalization error in terms of the accumulated path-dependent optimization error, terminal optimization error, number of samples, and number of iterations. For nonconvex smooth losses, we prove that full-batch GD efficiently generalizes close to any stationary point at termination, under the proper choice of a decreasing step size. Further, if the loss is nonconvex but the objective is PL, we derive vanishing bounds on the corresponding excess risk. For convex and strongly-convex smooth losses, we prove that full-batch GD generalizes even for large constant step sizes, and achieves a small excess risk while training fast. Our full-batch GD generalization error and excess risk bounds are significantly tighter than the existing bounds for (stochastic) GD, when the loss is smooth (but possibly non-Lipschitz).