 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Machine Learning Robustness in Covid-19 Genome Sequence Classification
Paper and Code
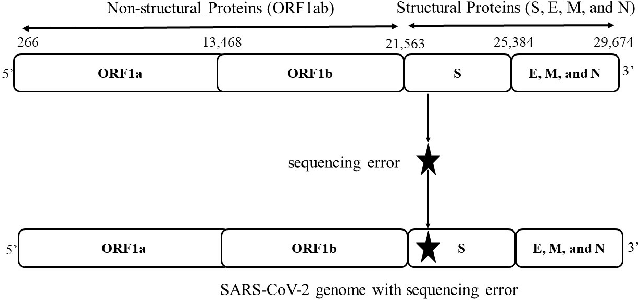
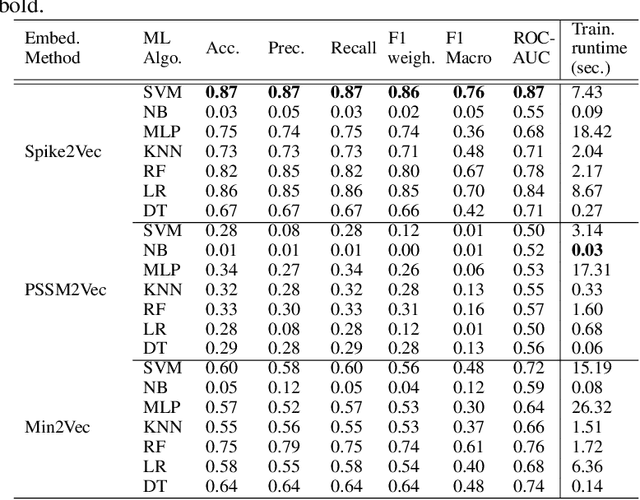
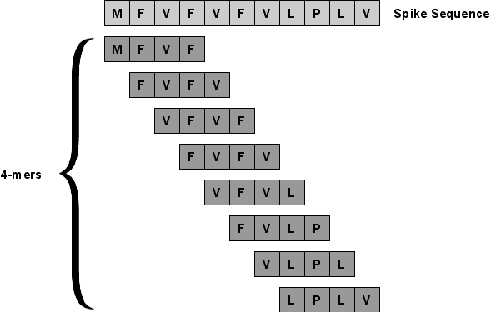
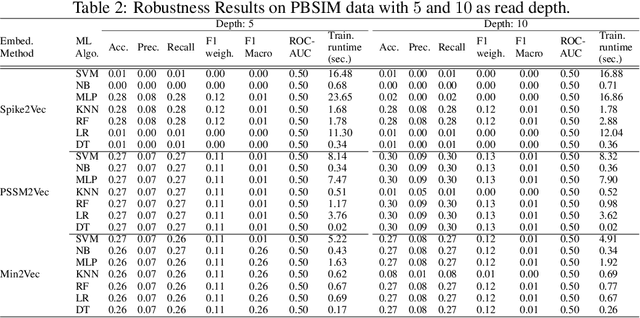
The rapid spread of the COVID-19 pandemic has resulted in an unprecedented amount of sequence data of the SARS-CoV-2 genome -- millions of sequences and counting. This amount of data, while being orders of magnitude beyond the capacity of traditional approaches to understanding the diversity, dynamics, and evolution of viruses is nonetheless a rich resource for machine learning (ML) approaches as alternatives for extracting such important information from these data. It is of hence utmost importance to design a framework for testing and benchmarking the robustness of these ML models. This paper makes the first effort (to our knowledge) to benchmark the robustness of ML models by simulating biological sequences with errors. In this paper, we introduce several ways to perturb SARS-CoV-2 genome sequences to mimic the error profiles of common sequencing platforms such as Illumina and PacBio. We show from experiments on a wide array of ML models that some simulation-based approaches are more robust (and accurate) than others for specific embedding methods to certain adversarial attacks to the input sequences. Our benchmarking framework may assist researchers in properly assessing different ML models and help them understand the behavior of the SARS-CoV-2 virus or avoid possible future pandemics.