 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBARA: Efficient Incentive Mechanism with Online Reward Budget Allocation in Cross-Silo Federated Learning
Paper and Code
May 16, 2023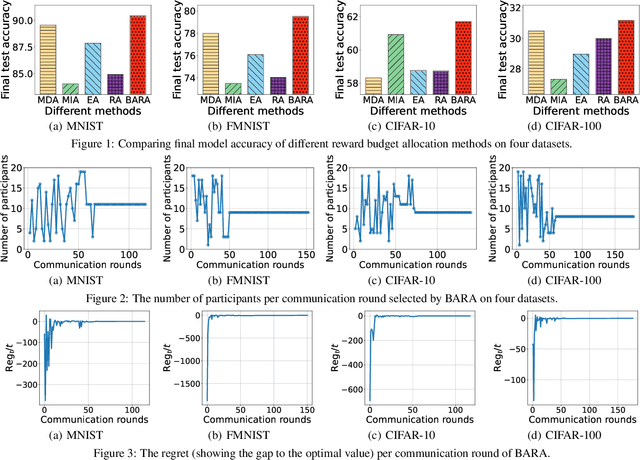
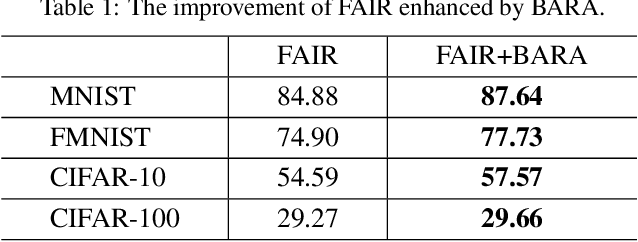
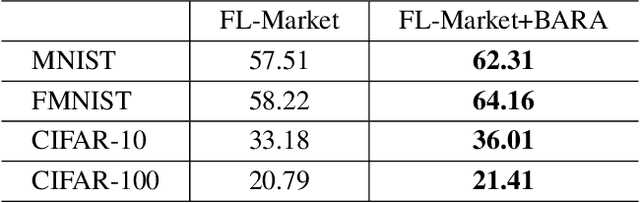
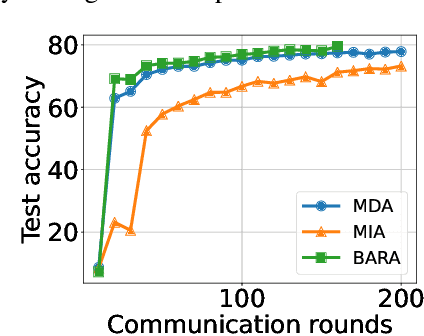
Federated learning (FL) is a prospective distributed machine learning framework that can preserve data privacy. In particular, cross-silo FL can complete model training by making isolated data islands of different organizations collaborate with a parameter server (PS) via exchanging model parameters for multiple communication rounds. In cross-silo FL, an incentive mechanism is indispensable for motivating data owners to contribute their models to FL training. However, how to allocate the reward budget among different rounds is an essential but complicated problem largely overlooked by existing works. The challenge of this problem lies in the opaque feedback between reward budget allocation and model utility improvement of FL, making the optimal reward budget allocation complicated. To address this problem, we design an online reward budget allocation algorithm using Bayesian optimization named BARA (\underline{B}udget \underline{A}llocation for \underline{R}everse \underline{A}uction). Specifically, BARA can model the complicated relationship between reward budget allocation and final model accuracy in FL based on historical training records so that the reward budget allocated to each communication round is dynamically optimized so as to maximize the final model utility. We further incorporate the BARA algorithm into reverse auction-based incentive mechanisms to illustrate its effectiveness. Extensive experiments are conducted on real datasets to demonstrate that BARA significantly outperforms competitive baselines by improving model utility with the same amount of reward budget.