 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Audio Captioning via Fusion of Low- and High- Dimensional Features
Paper and Code
Oct 10, 2022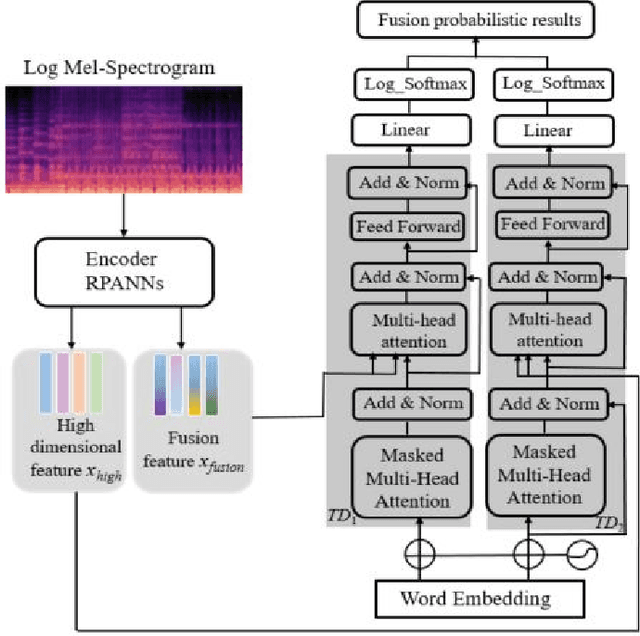
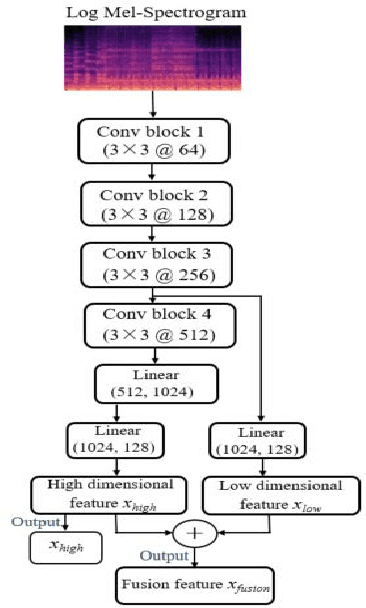
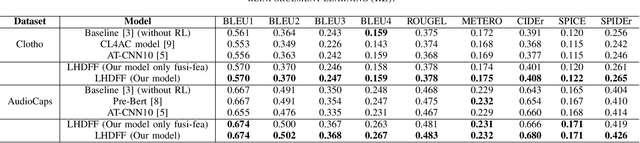
Automated audio captioning (AAC) aims to describe the content of an audio clip using simple sentences. Existing AAC methods are developed based on an encoder-decoder architecture that success is attributed to the use of a pre-trained CNN10 called PANNs as the encoder to learn rich audio representations. AAC is a highly challenging task due to its high-dimensional talent space involves audio of various scenarios. Existing methods only use the high-dimensional representation of the PANNs as the input of the decoder. However, the low-dimension representation may retain as much audio information as the high-dimensional representation may be neglected. In addition, although the high-dimensional approach may predict the audio captions by learning from existing audio captions, which lacks robustness and efficiency. To deal with these challenges, a fusion model which integrates low- and high-dimensional features AAC framework is proposed. In this paper, a new encoder-decoder framework is proposed called the Low- and High-Dimensional Feature Fusion (LHDFF) model for AAC. Moreover, in LHDFF, a new PANNs encoder is proposed called Residual PANNs (RPANNs) by fusing the low-dimensional feature from the intermediate convolution layer output and the high-dimensional feature from the final layer output of PANNs. To fully explore the information of the low- and high-dimensional fusion feature and high-dimensional feature respectively, we proposed dual transformer decoder structures to generate the captions in parallel. Especially, a probabilistic fusion approach is proposed that can ensure the overall performance of the system is improved by concentrating on the respective advantages of the two transformer decoders. Experimental results show that LHDFF achieves the best performance on the Clotho and AudioCaps datasets compared with other existing models