 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmented Transformer with Adaptive Graph for Temporal Action Proposal Generation
Paper and Code
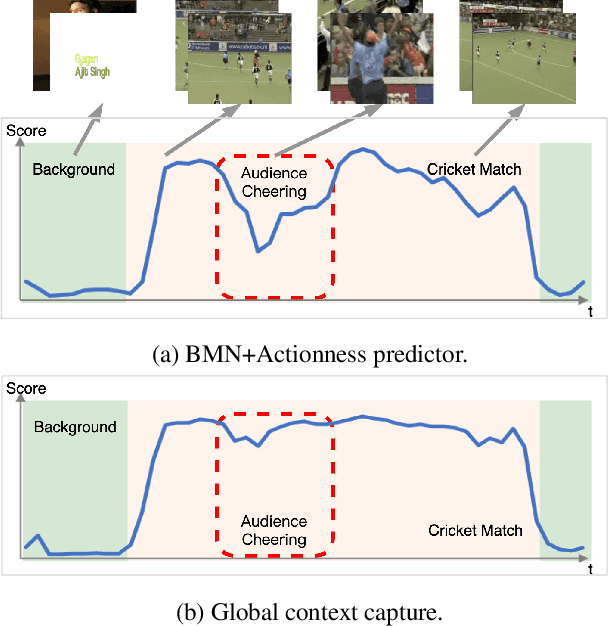

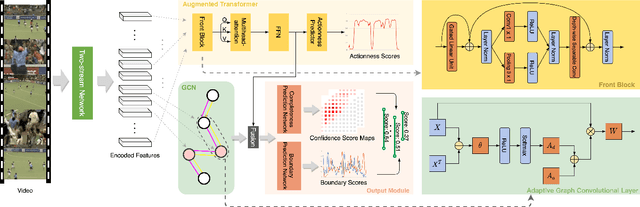
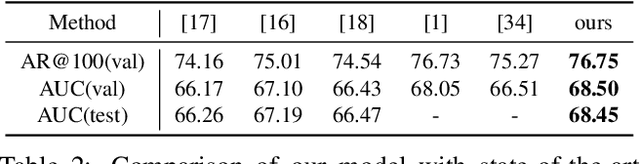
Temporal action proposal generation (TAPG) is a fundamental and challenging task in video understanding, especially in temporal action detection. Most previous works focus on capturing the local temporal context and can well locate simple action instances with clean frames and clear boundaries. However, they generally fail in complicated scenarios where interested actions involve irrelevant frames and background clutters, and the local temporal context becomes less effective. To deal with these problems, we present an augmented transformer with adaptive graph network (ATAG) to exploit both long-range and local temporal contexts for TAPG. Specifically, we enhance the vanilla transformer by equipping a snippet actionness loss and a front block, dubbed augmented transformer, and it improves the abilities of capturing long-range dependencies and learning robust feature for noisy action instances.Moreover, an adaptive graph convolutional network (GCN) is proposed to build local temporal context by mining the position information and difference between adjacent features. The features from the two modules carry rich semantic information of the video, and are fused for effective sequential proposal generation. Extensive experiments are conducted on two challenging datasets, THUMOS14 and ActivityNet1.3, and the results demonstrate that our method outperforms state-of-the-art TAPG methods. Our code will be released soon.