 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute-Guided Network for Cross-Modal Zero-Shot Hashing
Paper and Code
Feb 06, 2018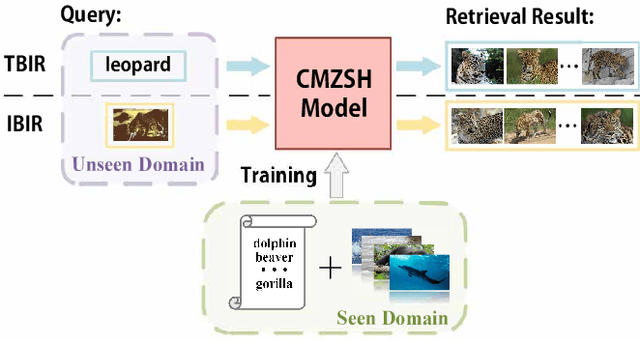



Zero-Shot Hashing aims at learning a hashing model that is trained only by instances from seen categories but can generate well to those of unseen categories. Typically, it is achieved by utilizing a semantic embedding space to transfer knowledge from seen domain to unseen domain. Existing efforts mainly focus on single-modal retrieval task, especially Image-Based Image Retrieval (IBIR). However, as a highlighted research topic in the field of hashing, cross-modal retrieval is more common in real world applications. To address the Cross-Modal Zero-Shot Hashing (CMZSH) retrieval task, we propose a novel Attribute-Guided Network (AgNet), which can perform not only IBIR, but also Text-Based Image Retrieval (TBIR). In particular, AgNet aligns different modal data into a semantically rich attribute space, which bridges the gap caused by modality heterogeneity and zero-shot setting. We also design an effective strategy that exploits the attribute to guide the generation of hash codes for image and text within the same network. Extensive experimental results on three benchmark datasets (AwA, SUN, and ImageNet) demonstrate the superiority of AgNet on both cross-modal and single-modal zero-shot image retrieval tasks.