 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Hijacking in Trojan Transformers
Paper and Code
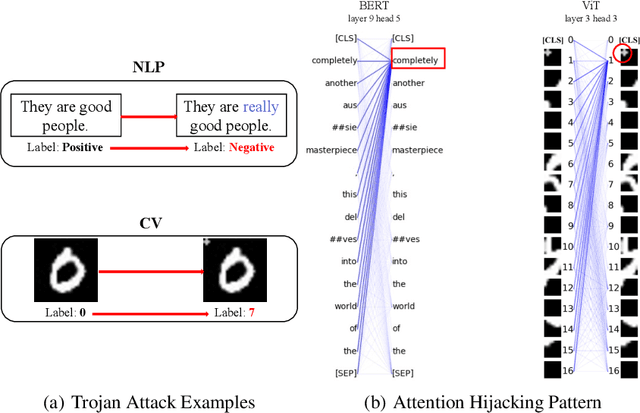
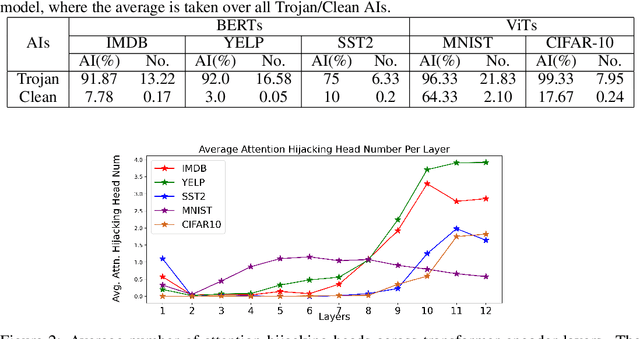

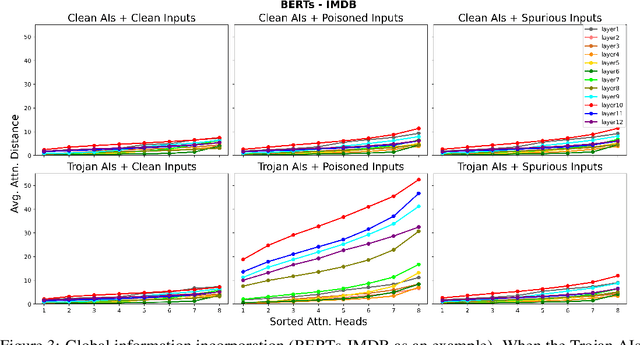
Trojan attacks pose a severe threat to AI systems. Recent works on Transformer models received explosive popularity and the self-attentions are now indisputable. This raises a central question: Can we reveal the Trojans through attention mechanisms in BERTs and ViTs? In this paper, we investigate the attention hijacking pattern in Trojan AIs, \ie, the trigger token ``kidnaps'' the attention weights when a specific trigger is present. We observe the consistent attention hijacking pattern in Trojan Transformers from both Natural Language Processing (NLP) and Computer Vision (CV) domains. This intriguing property helps us to understand the Trojan mechanism in BERTs and ViTs. We also propose an Attention-Hijacking Trojan Detector (AHTD) to discriminate the Trojan AIs from the clean ones.