 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-based Graph Neural Network for Semi-supervised Learning
Paper and Code
Mar 10, 2018
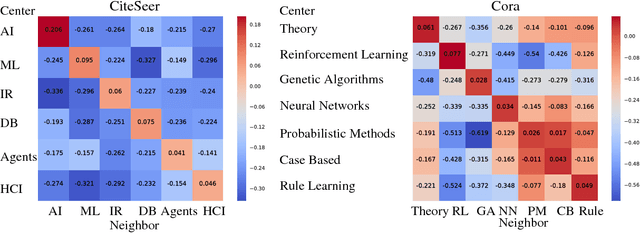
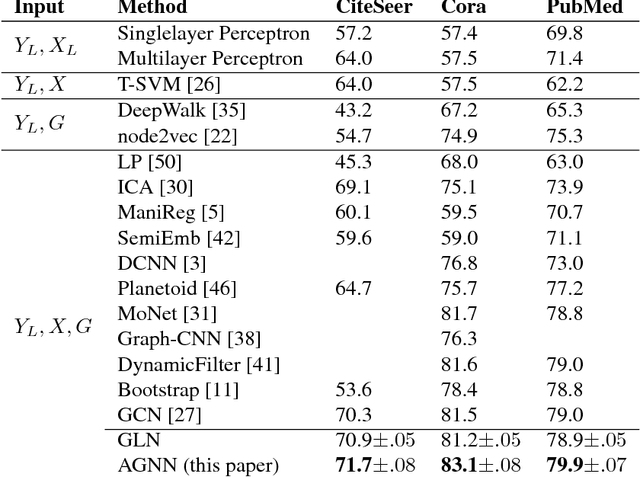
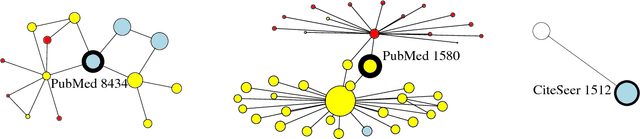
Recently popularized graph neural networks achieve the state-of-the-art accuracy on a number of standard benchmark datasets for graph-based semi-supervised learning, improving significantly over existing approaches. These architectures alternate between a propagation layer that aggregates the hidden states of the local neighborhood and a fully-connected layer. Perhaps surprisingly, we show that a linear model, that removes all the intermediate fully-connected layers, is still able to achieve a performance comparable to the state-of-the-art models. This significantly reduces the number of parameters, which is critical for semi-supervised learning where number of labeled examples are small. This in turn allows a room for designing more innovative propagation layers. Based on this insight, we propose a novel graph neural network that removes all the intermediate fully-connected layers, and replaces the propagation layers with attention mechanisms that respect the structure of the graph. The attention mechanism allows us to learn a dynamic and adaptive local summary of the neighborhood to achieve more accurate predictions. In a number of experiments on benchmark citation networks datasets, we demonstrate that our approach outperforms competing methods. By examining the attention weights among neighbors, we show that our model provides some interesting insights on how neighbors influence each other.