 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttend to the Difference: Cross-Modality Person Re-identification via Contrastive Correlation
Paper and Code
Oct 25, 2019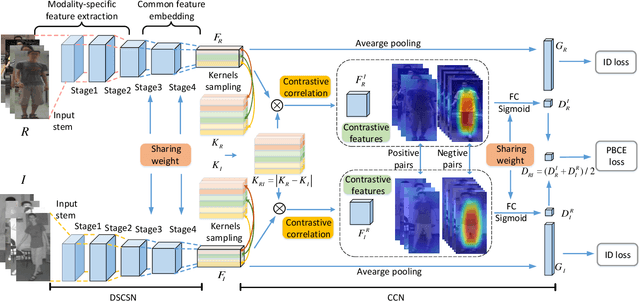

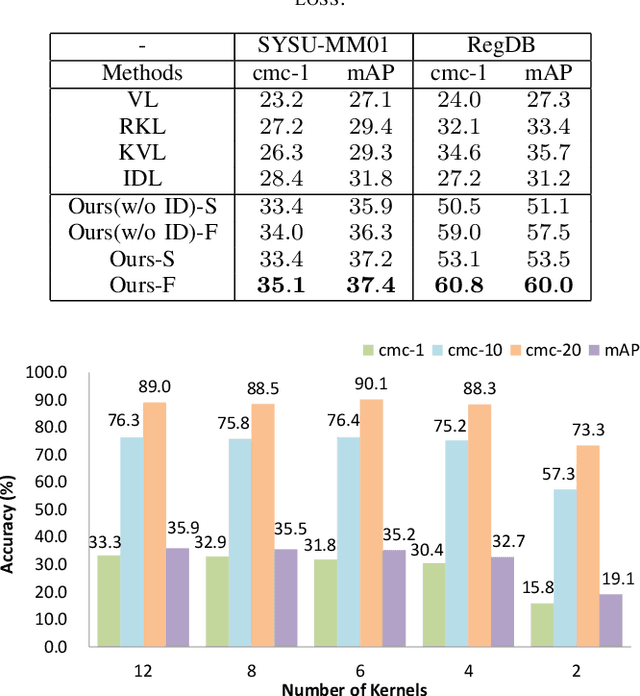
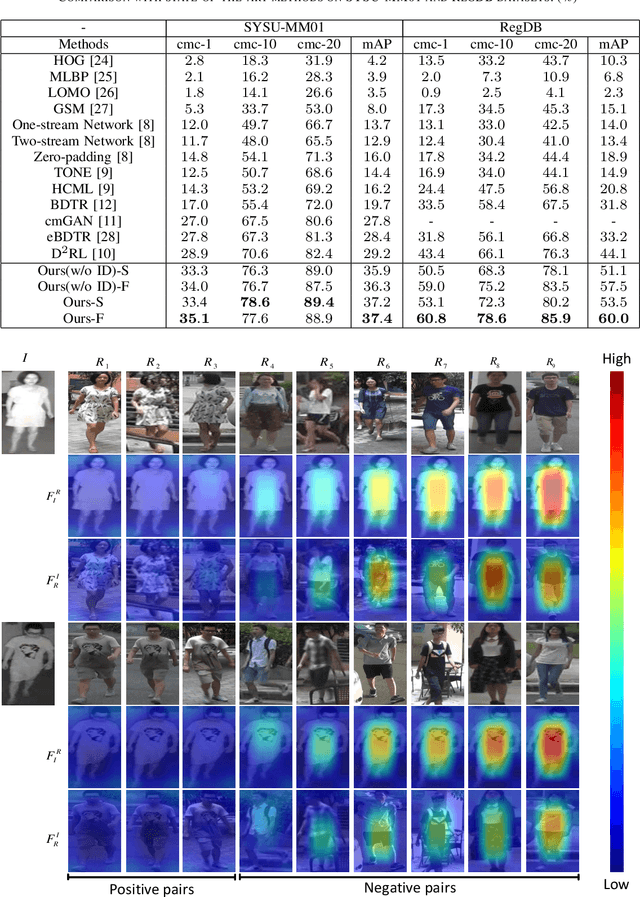
The problem of cross-modality person re-identification has been receiving increasing attention recently, due to its practical significance. Motivated by the fact that human usually attend to the difference when they compare two similar objects, we propose a dual-path cross-modality feature learning framework which preserves intrinsic spatial strictures and attends to the difference of input cross-modality image pairs. Our framework is composed by two main components: a Dual-path Spatial-structure-preserving Common Space Network (DSCSN) and a Contrastive Correlation Network (CCN). The former embeds cross-modality images into a common 3D tensor space without losing spatial structures, while the latter extracts contrastive features by dynamically comparing input image pairs. Note that the representations generated for the input RGB and Infrared images are mutually dependant to each other. We conduct extensive experiments on two public available RGB-IR ReID datasets, SYSU-MM01 and RegDB, and our proposed method outperforms state-of-the-art algorithms by a large margin with both full and simplified evaluation modes.