 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATCSpeech: a multilingual pilot-controller speech corpus from real Air Traffic Control environment
Paper and Code
Nov 26, 2019
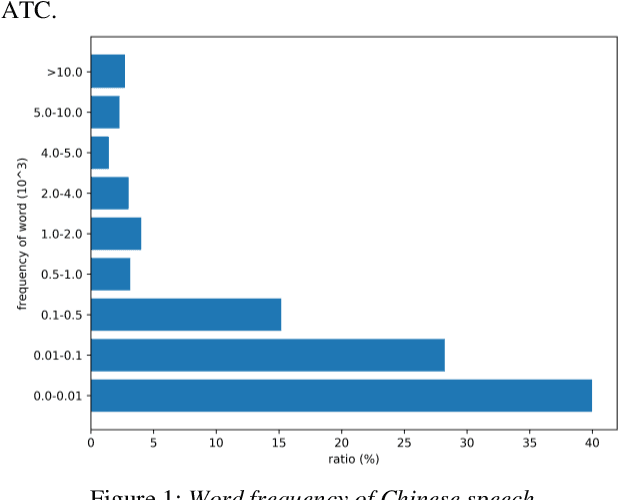
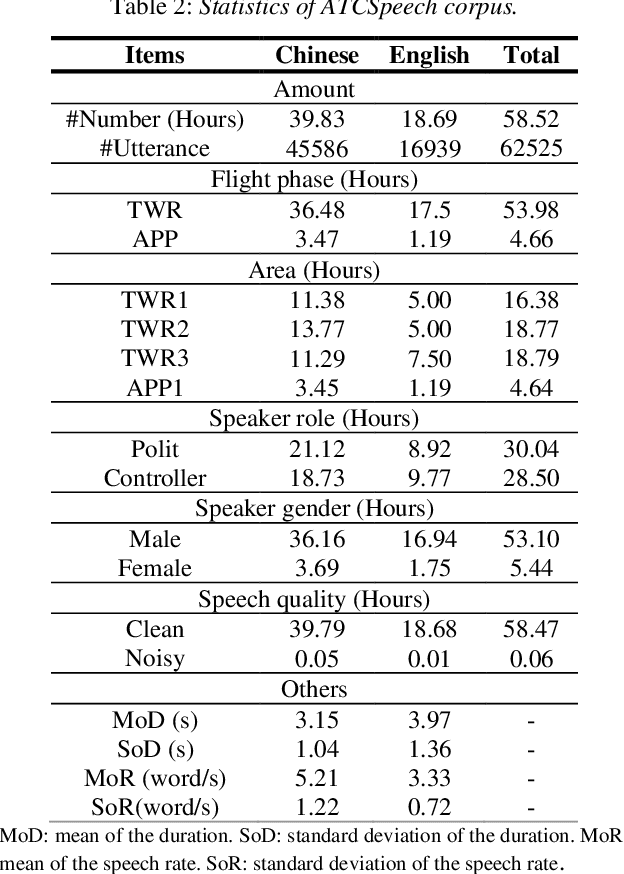

Automatic Speech Recognition (ASR) is greatly developed in recent years, which expedites many applications on other fields. For the ASR research, speech corpus is always an essential foundation, especially for the vertical industry, such as Air Traffic Control (ATC). There are some speech corpora for common applications, public or paid. However, for the ATC, it is difficult to collect raw speeches from real systems due to safety issues. More importantly, for a supervised learning task like ASR, annotating the transcription is a more laborious work, which hugely restricts the prospect of ASR application. In this paper, a multilingual speech corpus (ATCSpeech) from real ATC systems, including accented Mandarin Chinese and English, is built and released to encourage the non-commercial ASR research in ATC domain. The corpus is detailly introduced from the perspective of data amount, speaker gender and role, speech quality and other attributions. In addition, the performance of our baseline ASR models is also reported. A community edition for our speech database can be applied and used under a special contrast. To our best knowledge, this is the first work that aims at building a real and multilingual ASR corpus for the air traffic related research.