 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Generalization of SGD via Disagreement
Paper and Code
Jun 25, 2021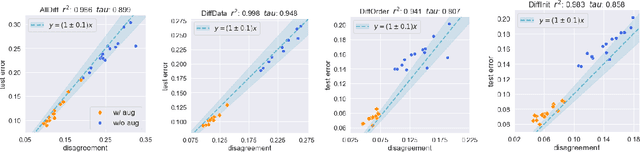

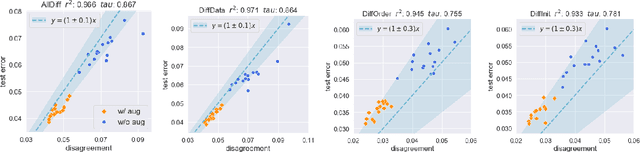

We empirically show that the test error of deep networks can be estimated by simply training the same architecture on the same training set but with a different run of Stochastic Gradient Descent (SGD), and measuring the disagreement rate between the two networks on unlabeled test data. This builds on -- and is a stronger version of -- the observation in Nakkiran & Bansal '20, which requires the second run to be on an altogether fresh training set. We further theoretically show that this peculiar phenomenon arises from the \emph{well-calibrated} nature of \emph{ensembles} of SGD-trained models. This finding not only provides a simple empirical measure to directly predict the test error using unlabeled test data, but also establishes a new conceptual connection between generalization and calibration.