 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASDOT: Any-Shot Data-to-Text Generation with Pretrained Language Models
Paper and Code
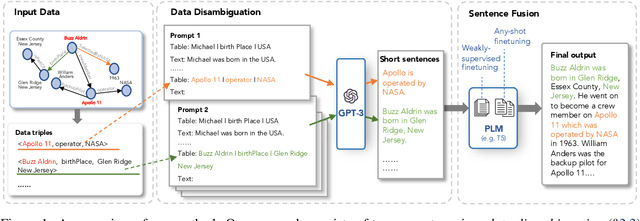

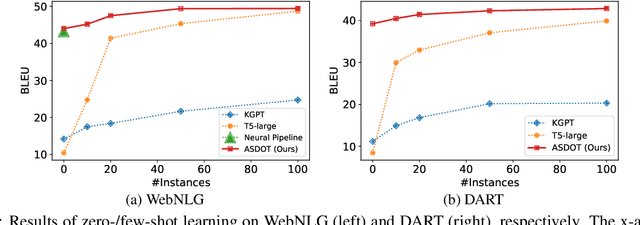

Data-to-text generation is challenging due to the great variety of the input data in terms of domains (e.g., finance vs sports) or schemata (e.g., diverse predicates). Recent end-to-end neural methods thus require substantial training examples to learn to disambiguate and describe the data. Yet, real-world data-to-text problems often suffer from various data-scarce issues: one may have access to only a handful of or no training examples, and/or have to rely on examples in a different domain or schema. To fill this gap, we propose Any-Shot Data-to-Text (ASDOT), a new approach flexibly applicable to diverse settings by making efficient use of any given (or no) examples. ASDOT consists of two steps, data disambiguation and sentence fusion, both of which are amenable to be solved with off-the-shelf pretrained language models (LMs) with optional finetuning. In the data disambiguation stage, we employ the prompted GPT-3 model to understand possibly ambiguous triples from the input data and convert each into a short sentence with reduced ambiguity. The sentence fusion stage then uses an LM like T5 to fuse all the resulting sentences into a coherent paragraph as the final description. We evaluate extensively on various datasets in different scenarios, including the zero-/few-/full-shot settings, and generalization to unseen predicates and out-of-domain data. Experimental results show that ASDOT consistently achieves significant improvement over baselines, e.g., a 30.81 BLEU gain on the DART dataset under the zero-shot setting.