 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Joint Face Spoofing and Forgery Detection with Visual and Physiological Cues
Paper and Code
Aug 10, 2022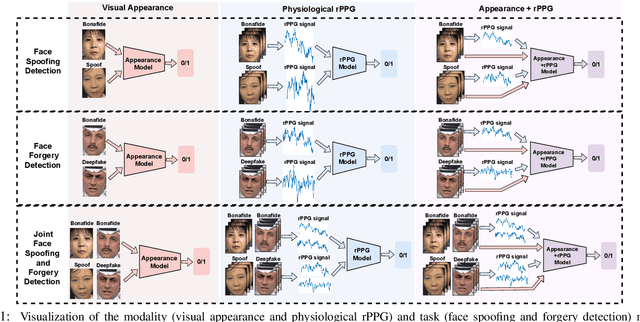

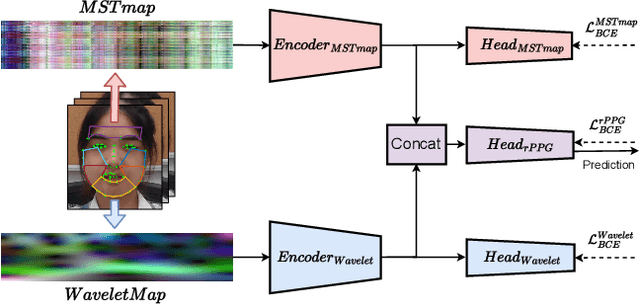

Face anti-spoofing (FAS) and face forgery detection play vital roles in securing face biometric systems from presentation attacks (PAs) and vicious digital manipulation (e.g., deepfakes). Despite promising performance upon large-scale data and powerful deep models, the generalization problem of existing approaches is still an open issue. Most of recent approaches focus on 1) unimodal visual appearance or physiological (i.e., remote photoplethysmography (rPPG)) cues; and 2) separated feature representation for FAS or face forgery detection. On one side, unimodal appearance and rPPG features are respectively vulnerable to high-fidelity face 3D mask and video replay attacks, inspiring us to design reliable multi-modal fusion mechanisms for generalized face attack detection. On the other side, there are rich common features across FAS and face forgery detection tasks (e.g., periodic rPPG rhythms and vanilla appearance for bonafides), providing solid evidence to design a joint FAS and face forgery detection system in a multi-task learning fashion. In this paper, we establish the first joint face spoofing and forgery detection benchmark using both visual appearance and physiological rPPG cues. To enhance the rPPG periodicity discrimination, we design a two-branch physiological network using both facial spatio-temporal rPPG signal map and its continuous wavelet transformed counterpart as inputs. To mitigate the modality bias and improve the fusion efficacy, we conduct a weighted batch and layer normalization for both appearance and rPPG features before multi-modal fusion. We find that the generalization capacities of both unimodal (appearance or rPPG) and multi-modal (appearance+rPPG) models can be obviously improved via joint training on these two tasks. We hope this new benchmark will facilitate the future research of both FAS and deepfake detection communities.