 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Evaluation of Multi-Agent Deep Reinforcement Learning Algorithms
Paper and Code
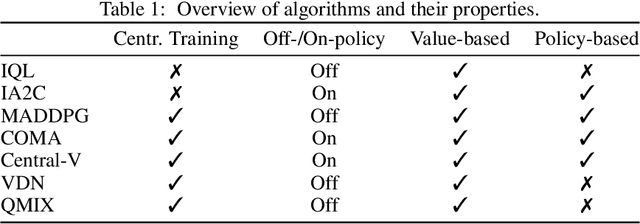
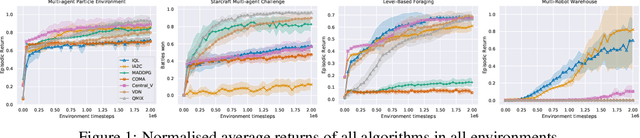
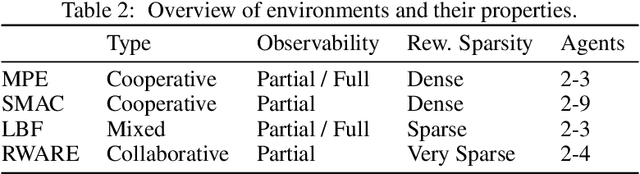
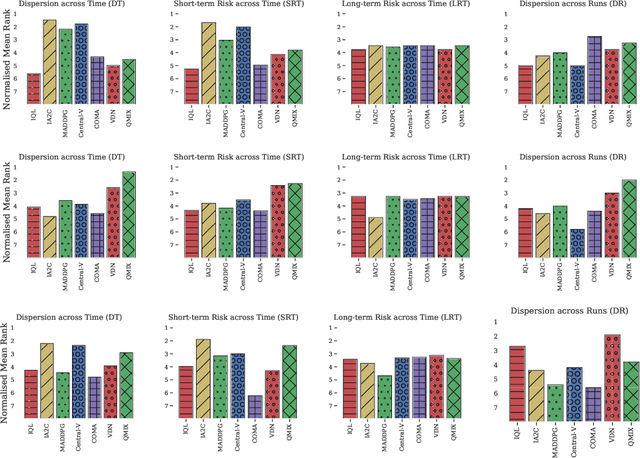
Multi-agent deep reinforcement learning (MARL) suffers from a lack of commonly-used evaluation tasks and criteria, making comparisons between approaches difficult. In this work, we evaluate and compare three different classes of MARL algorithms (independent learners, centralised training with decentralised execution, and value decomposition) in a diverse range of multi-agent learning tasks. Our results show that (1) algorithm performance depends strongly on environment properties and no algorithm learns efficiently across all learning tasks; (2) independent learners often achieve equal or better performance than more complex algorithms; (3) tested algorithms struggle to solve multi-agent tasks with sparse rewards. We report detailed empirical data, including a reliability analysis, and provide insights into the limitations of the tested algorithms.