 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAppending Adversarial Frames for Universal Video Attack
Paper and Code
Dec 10, 2019


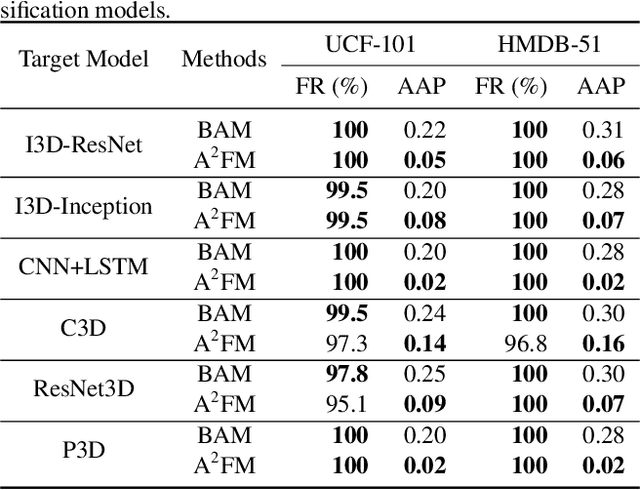
There have been many efforts in attacking image classification models with adversarial perturbations, but the same topic on video classification has not yet been thoroughly studied. This paper presents a novel idea of video-based attack, which appends a few dummy frames (e.g., containing the texts of `thanks for watching') to a video clip and then adds adversarial perturbations only on these new frames. Our approach enjoys three major benefits, namely, a high success rate, a low perceptibility, and a strong ability in transferring across different networks. These benefits mostly come from the common dummy frame which pushes all samples towards the boundary of classification. On the other hand, such attacks are easily to be concealed since most people would not notice the abnormality behind the perturbed video clips. We perform experiments on two popular datasets with six state-of-the-art video classification models, and demonstrate the effectiveness of our approach in the scenario of universal video attacks.